[2026 SWING magazine] 퍼징의 개념, 구현 그리고 취약점 분석까지
Fuzzing의 개념과 역사
Fuzzing의 기본 원리
Fuzzing의 정의
Fuzzing(퍼징) 또는 Fuzz Testing은 보안 취약점을 찾기 위한 자동화된 테스트 기술로 시스템에 의도적으로 잘못된 데이터나 무작위 데이터를 입력하여 비정상적인 동작(크래시, 무한 루프, 예외, 메모리 누수 등)이 발생하는지 확인하는 기술이다. 프로그램이이 복잡할수록 많은 버그와 attack surface가 생기는데 이에 대해 수동 테스트보다 퍼징은 입력을 자동으로 생성 및 변형하여 대규모의 테스트를 수행한다는 점에서 더 효율적일 수 있다.
예를 들어, 문자열 입력을 요구하는 프로그램에 정상적인 사용자 이름 대신 과도하게 긴 문자열, 특수문자 집합, 혹은 이진 데이터와 같은 입력을 제공하는 경우, 프로그램이 충돌(crash)하거나 예외적 동작을 보일 수 있다. 이와 같이 퍼징은 자동화된 입력 변형을 통해 예상치 못한 실행 경로를 탐색함으로써 잠재적인 결함을 효과적으로 발견한다.
Fuzzing의 반복 구조
퍼징은 “시드 입력(seed input) → 변형(mutation) → 실행(execution) → 관찰(observation)”의 반복적 루프를 기반으로 한다. 첫째, 시드 입력은 프로그램이 정상적으로 처리할 수 있는 최소한의 입력으로, 퍼징 과정의 출발점이 된다. 둘째, 시드 입력은 다양한 기법을 통해 변형되어 새로운 테스트 입력으로 생성된다. 변형 기법에는 비트 단위 변경, 길이 확장, 구조적 조작 등이 포함될 수 있다. 셋째, 변형된 입력은 대상 프로그램에 제공되어 실제 실행이 이루어진다. 마지막으로, 실행 결과가 관찰되며, 해당 과정에서 충돌 발생 여부, 예외적 동작, 또는 새로운 코드 경로의 탐색 여부가 기록된다. 이러한 과정은 자동화된 루프를 통해 수천에서 수백만 회 이상 반복되며, 결과적으로 기존의 수동 테스트로는 발견하기 어려운 잠재적 결함을 효율적으로 탐지할 수 있다.
Fuzzing을 수행하는 이유
퍼징이 효과적인 소프트웨어 테스트 및 보안 검증 기법으로 자리매김한 이유는 자동화, 규모, 실용성의 세 가지 측면에서 설명될 수 있다. 첫째, 자동화 측면에서 퍼징은 사람이 직접 입력을 설계하거나 실행을 관리할 필요 없이, 대상 프로그램에 퍼징을 수행하는 프로그램인 퍼저(fuzzer)가 입력 생성과 실행, 관찰의 전 과정을 자동으로 수행한다. 둘째, 규모의 측면에서 퍼징은 컴퓨터의 연산 능력을 활용하여 단기간에 방대한 수의 입력을 테스트할 수 있다. 이로써 인간이 수동적으로 수행하기 어려운 대규모 탐색이 가능하다. 셋째, 실용성 측면에서 퍼징은 프로그램의 내부 구조에 대한 정적 분석 없이도 단순히 실행과 관찰을 통해 취약점을 발견할 수 있다는 장점을 지닌다. 이러한 특성으로 인해 퍼징은 대규모 소프트웨어 기업에서 실제 산업 환경에 광범위하게 도입되고 있다.
Fyzzing의 역사
초기 Fuzzing(1989~1999)
퍼징이라는 개념은 1989년, 미국 위스콘신 대학교 매디슨(University of Wisconsin-Madison)의 Barton Miller 교수에 의해 처음 제안되었다. 당시 Miller 교수는 프로그램 안정성 테스트를 위해 다양한 UNIX 프로그램을 대상으로, 무작위(Random) 데이터를 입력하는 방식으로 프로그램의 반응을 관찰하는 실험을 하고 있었다. 그 결과, 많은 프로그램들이 정상적인 입력이 아닌 임의의 데이터를 받았을 때 쉽게 비정상 종료되거나 예상치 못한 오류를 발생시킨다는 사실이 밝혀졌다. 이 연구는 소프트웨어가 예외적인 입력을 처리하는 능력이 부족하다는 점을 입증하였으며, 이를 통해 “Fuzzing”이라는 새로운 테스트 기법이 탄생하게 되었다. 이후 1990년대 후반으로 접어들며 Fuzzing은 학술 연구뿐 아니라 실무적인 테스트에도 활용되기 시작하였다. 특히, 1999년에는 핀란드의 Oulu 대학교에서 PROTOS Test Suite 개발을 시작하였다. PROTOS 프로젝트는 프로토콜(Protocol)을 대상으로 한 Fuzzing 테스트를 목표로 하였으며, 이는 단순 무작위 입력에 머물렀던 초기 Fuzzing 기법을 특정 도메인에 특화된 방향으로 확장시킨 사례라 할 수 있다.
Fuzzing 다양화 (2000~2006)
2000년대 초반은 퍼징이 학문적 연구를 넘어 실질적인 보안 도구로 발전하기 시작한 시기였다.
가) PROTOS SNMP Test Suite
2002년, Oulu 대학교는 SNMP(Simple Network Management Protocol) 을 대상으로 한 PROTOS SNMP Test Suite를 발표하였다. 이 Test Suite는 네트워크 장비의 보안성을 검증하기 위해 사용되었으며, 발표 직후 전 세계적으로 사용 중인 수많은 라우터와 스위치에서 심각한 취약점들이 발견되었다. 이는 Fuzzing이 단순히 연구적 호기심을 충족시키는 기법을 넘어, 산업 현장에서 실질적인 보안 사고를 예방할 수 있는 유용한 도구임을 입증한 사례였다.
나) SPIKE
같은 해, 보안 연구자 Dave Aitel은 BlackHat USA 2002에서 SPIKE라는 퍼징 프레임워크를 공개하였다. SPIKE는 프로토콜 분석과 입력 생성 기능을 갖춘 도구로서, 연구자들이 보다 손쉽게 네트워크 기반 퍼징을 수행할 수 있도록 하였다. SPIKE는 이후 다양한 퍼징 도구의 기반이 되었으며, 특히 보안 연구 커뮤니티 내에서 널리 활용되었다.
다) Mangleme와 웹 보안 연구
2004년에는 Michael Zalewski(lcamtuf) 가 Mangleme라는 퍼저를 발표하였다. 이 도구는 HTML 파서와 웹 브라우저를 대상으로 한 랜덤 입력 기반 퍼징을 수행하였고, 이를 통해 당시 널리 사용되던 웹 브라우저들에서 수많은 보안 결함이 발견되었다. Mangleme는 웹 보안 연구에 있어 퍼징이 핵심적인 역할을 수행할 수 있음을 보여준 대표적 사례로 평가된다.
라) 상업용 퍼저와 ActiveX Fuzzer
2005년에는 FileFuzz, SPIKEfile 등 다양한 파일 포맷 기반 퍼저가 등장하였다. 더불어, Codenomicon과 같은 기업들은 퍼징을 상업적인 형태로 제공하기 시작하였으며, 이는 보안 테스트 시장에서 퍼징의 상용화 가능성을 열었다.2006년에는 ActiveX 취약점 분석을 위해 COMRider(David Zimmer) 와 AxMan(HD Moore) 과 같은 퍼저가 등장하였다. 또한 Hamachi와 CSSDIE가 발표되며 클라이언트·웹 보안 분야에서도 퍼징이 활발히 적용되었다. 이 시기 퍼징은 학계와 연구실의 실험 도구에서 벗어나, 산업계에서 널리 사용되는 보안 검증 수단으로 자리 잡기 시작하였다.
AFL Fuzzing(2013~)
퍼징 역사에서 또 하나의 전환점은 AFL(American Fuzzy Lop)의 등장이었다. 2013년, Michael Zalewski는 AFL을 공개하였다. AFL은 기존의 무작위 퍼징과 달리, 커버리지 기반 퍼징(Coverage-guided Fuzzing) 기법을 도입하였다. 이는 프로그램의 실행 경로를 측정하고, 새로운 코드 경로를 탐색할 수 있는 입력을 우선적으로 생성하는 방식으로, 퍼징의 효율성을 비약적으로 향상시켰다.AFL의 성공 이후 다양한 파생 도구들이 등장하였다.
■ AFLFast는 마르코프 체인 기반의 모델을 통해 희귀한 실행 경로를 더 적극적으로 탐색하였다.
■ AFLGo는 타깃 지점(Targeted Location)에 도달하는 것을 목표로 하여, 취약점이 존재할 가능성이 높은 코드 영역까지 도달하는 데 최적화되었다.
■ Angora는 분기 조건을 해결하기 위해 유도 기법(gradient descent) 을 적용하여 기존 퍼저가 넘기 힘들었던 조건문을 효과적으로 우회할 수 있었다.
이러한 AFL 계열의 발전은 퍼징을 대규모 소프트웨어 테스트 및 보안 연구의 주류 기법으로 정착시키는 데 결정적인 역할을 하였다.
Whitebox Fuzzer(2008~)
AFL 계열이 커버리지 기반의 “Black-box”에 가까운 접근법을 취했다면, 이와는 달리 White-box Fuzzing 은 프로그램의 내부 구조와 제어 흐름을 분석하여 입력을 생성하는 방식으로 발전하였다.대표적인 사례로, 2008년 Microsoft에서 개발한 SAGE는 Symbolic Execution 기법을 도입하여, 프로그램의 실행 경로를 수학적 제약 조건으로 변환한 뒤 이를 해석하여 새로운 입력을 생성하였다. 이 접근 방식은 단순 무작위 입력으로는 도달하기 어려운 깊은 실행 경로를 탐색하는 데 탁월한 성능을 발휘하였다.이후 연구에서는 퍼징과 심볼릭 실행을 결합한 하이브리드 기법이 등장하였다. Driller(2016) 는 AFL과 심볼릭 실행을 통합하여, 퍼저가 탐색하기 어려운 지점에서 심볼릭 실행을 활용하는 방식을 제안하였다. 이어서 QSYM(2018) 은 기존 심볼릭 실행의 성능 문제를 개선하기 위해 효율적인 concolic execution 방식을 도입하였다. 이러한 발전은 퍼징이 단순히 랜덤 기반의 테스트 기법을 넘어, 프로그램 분석과 결합된 정교한 연구 영역으로 확장되었음을 의미한다.
도메인 특화 Fuzzer(2016~)
퍼징 연구는 최근 들어 특정 도메인에 특화된 형태로 발전하고 있다. 대표적인 예가 Google에서 개발한 Syzkaller(2016) 이다. Syzkaller는 Linux 커널의 시스템 호출(Syscall)을 대상으로 한 퍼저로, 대규모 분산 환경에서 자동화된 커널 퍼징을 수행할 수 있도록 설계되었다. Syzkaller는 수백 개의 커널 취약점을 발견하는 데 기여하였으며, 운영체제 보안 강화에 핵심적인 역할을 수행하였다.이외에도 산업용 제어 시스템(ICS) 프로토콜, IoT 장비, 웹 브라우저, 자율주행 소프트웨어 등 특정 환경에 최적화된 도메인 특화 퍼저들이 활발히 연구되고 있다. 이러한 경향은 퍼징이 더 이상 범용적 소프트웨어 테스트 도구에 머무르지 않고, 각 산업 분야의 요구에 맞추어 발전하고 있음을 보여준다.
Fuzzing의 종류
소소코드 의존성과 프로그램 분석 정도에 따라 Fuzzing을 분류할 수 있다.
Black-box Fuzzing
블랙박스 퍼징은 대상 프로그램의 내부 구조나 동작 원리에 대한 정보를 고려하지 않고, 오직 외부에서 관찰 가능한 입력과 출력에만 의존하여 수행되는 퍼징 기법이다. 이 접근법은 프로그램을 완전히 “검은 상자(black box)”로 간주하며, 입력 공간을 무작위로 탐색하거나 단순한 변형 기법을 적용하여 새로운 테스트 케이스를 생성한다. 블랙박스 퍼징의 장점은 구현이 단순하고, 대상 프로그램의 내부 코드에 접근할 수 없는 상황에서도 적용 가능하다는 점이다. 그러나 내부 실행 경로에 대한 피드백이 없기 때문에 코드 커버리지 향상에 한계가 있어 탐지 효율성이 상대적으로 낮을 수 있다. 이와 같은 특성으로 인해 블랙박스 퍼징은 초기 퍼징 연구에서 널리 사용되었으나, 현재는 보다 정교한 기법에 의해 보완되는 추세이다.대표적으로 다음과 같은 테스트 기법이 수행 가능하다.
■ Dumb Based Test
■ Decison Table Test (의사 결정 테이블 테스트)
■ Syntax Test
■ Use Case Test
■ User Story Test
White-Box Fuzzing
화이트박스 퍼징은 프로그램의 내부 구조와 동작 원리에 대한 정보를 최대한 활용하는 퍼징 기법으로, 특히 정적 분석과 심볼릭 실행(symbolic execution)과 같은 기법을 결합하는 형태로 구현된다. 이 접근법에서는 프로그램의 경로 조건(path condition)을 수학적 제약식으로 모델링하고, 제약 해결기(constraint solver)를 이용하여 새로운 입력을 생성한다.화이트박스 퍼징의 가장 큰 장점은 코드 경로를 체계적으로 탐색할 수 있다는 점으로, 이론적으로는 입력 공간을 높은 정밀도로 커버할 수 있다. 그러나 실행 오버헤드와 제약 해결기의 복잡성으로 인해 대규모 소프트웨어에 적용하기 어렵다는 한계가 존재한다. 또한, 경로 폭발(path explosion) 문제로 인해 실용적 활용성에서 제약을 받는 경우가 많다.따라서 화이트박스 퍼징은 정밀 분석이 요구되는 특정 상황이나 제한된 코드 영역에 집중적으로 적용되는 경우가 많으며, 최근에는 이를 보완하기 위해 하이브리드 퍼징(hybrid fuzzing) 기법이 연구되고 있다.소스 코드에 접근할 수 있기 때문에 다음과 같은 테스트 기법이 수행 가능하다.
■ Control-Flow Test (제어 흐름 테스트)
■ Data Flow Test (데이터 흐름 테스트)
■ Brach Test (분기 테스트)
■ Prime Path Test (주요 경로 테스트)
■ Path Test (경로 테스트)
Gray-box Fuzzing
그레이박스 퍼징은 블랙박스와 화이트박스 퍼징의 중간적 접근 방식으로, 대상 프로그램의 내부 정보를 부분적으로 활용하는 퍼징 기법이다. 대표적으로 코드 커버리지(code coverage) 정보를 수집하여 입력 변형 과정에 피드백을 제공하는 방법이 널리 사용된다.이 방식은 블랙박스 퍼징의 단순성과 화이트박스 퍼징의 정밀성을 절충하여, 취약점 탐지 효율을 높일 수 있다. 특히 AFL(American Fuzzy Lop)과 같은 커버리지 기반 그레이박스 퍼저는 학계와 산업계 모두에서 표준 도구로 자리매김하였으며, 실질적으로 발견된 보안 취약점의 상당수가 해당 접근법을 통해 보고되었다.그레이박스 퍼징은 입력의 변형 과정에서 실행 경로 정보를 활용함으로써 새로운 경로 탐색을 촉진하고, 결과적으로 탐지 범위를 확장하는 효과를 갖는다.
대표적으로 다음과 같은 테스트 기법이 수행 가능하다.
■ Matrix Test (행렬 테스트)
■ Regression Test (회귀 테스트)
■ Pattern Test (패턴 테스트)
■ Orthogonal Array Test (직교 배열 테스트)
Fuzzing 알고리즘
ALGORITHM 1: Fuzz Testing

위 사진은 fuzz testing을 위한 보편적인 알고리즘인 ALGORITHM 1을 의사 코드로 나타낸 것이다. 해당 알고리즘은 퍼징이 단순히 입력을 무작위로 변형하여 실행하는 과정이 아니라, 일련의 체계적인 단계를 거치는 반복적 알고리즘임을 보여준다.
ALGORITHM 1은 fuzz configuration set인 ℂ와 timeout인 𝑡limit을 입력으로 사용하고, 발견한 버그들의 set 𝔹를 출력한다. 크게 두 파트로 구성되는데 첫 번째 파트는 fuzz campaign이 시작될 때 실행되는 PREPROCESS 단계이다. 두 번재 파트는 loop 안에서 연속되는 다섯 가지 단계들이다.
■ SCHEUDULE
■ INPUTGEN
■ INPUTEVAL
■ CONFUPDATE
■ CONTINUE
해당 loop의 각 실행을 fuzz intertaion 이라고 하고, INPUTEVAL이 test case에서 PUT을 실행하는 각 행위를 fuzz run 이라고 한다. 모든 Fuzzer가 다섯 가지 단계를 다 구현하는 것은 아니다. 예를 들어, fuzz configuration의 set을 업데이트하지 않는 Radamas를 모델링하면 CONFUPDATE는 configuration set을 그대로 return한다. 이제 의사 코드를 살펴보자.
가) PREPROCESS(ℂ) → ℂ
PPREPROCESS는 fuzz configuration을 input으로 받아 수정하고 반환한다. fuzz algorithm마다 다른 동작을 하며 PUT에 Instrumentaion code를 삽입하거나 seed file의 실행 속도를 측정하는 등 다양한 작업을 수행할 수 있다.
나) SCHECULE(ℂ, 𝑡elapsed, 𝑡limit)) → conf
SCHECULE은 현재 fuzz configuration set, curren time인 𝑡elapsed, timeout인 𝑡limit)을 input으로 받아 현재 iteration에 적용시킬 configuration(conf)을 선택한다.
다) INPUTGEN(conf) → tcs
INPUTGEN은 fuzz configuration을 input으로 받아 teset case set인 tcs를 리턴한다. test case를 모을 때, INPUTGEN은 conf에서 특정한 parameter를 사용하고 test case를 생성하기 위해 conf에 있는 seed를 사용해 input을 생성하거나 model 혹은 문법을 parameter로 사용하기도 한다.
라) INPUTEVAL(conf, tcs, Obug) → 𝔹’, execinfos
INPUTEVAL은 fuzz configuration인 conf와 teset case의 set인 tcs, bug oracle인 Obug를 input으로 받아 tcs에서 PUT을 실행하고 해당 실행이 보안 정책에 어긋나는 행동을 유발하는지 여부를 Obug를 사용하여 확인한다. 그런 다음 발견된 버그의 set인 𝔹와 각 fuzz run에 대한 정보인 execinfos를 반환한다. 이후 execinfos는 fuzz configuration update에 사용된다.
마) CONFUPDATE(ℂ, conf, execinfos) → ℂ
CONFUPDATE는 fuzz configuration set인 ℂ, 현재 configuration인 conf, 각 fuzz run에 대한 정보인 execinfos를 input으로 받고 fuzz configuration set인 ℂ를 업데이트 한다. 예를 들어, 많은 Gray-box fuzzer들은 execinfos를 통해 fuzz configuarion의 수를 줄이는 작업을 한다.
바) CONTINUE(ℂ) → {True, Flase}
CONTINUE는 fuzz configuration set인 ℂ를 input으로 받고 fuzz iteration의 실행 여부를 나타내는 boolean을 리턴한다. 해당 함수는 White-box fuzzer에서 더 이상 발견할 path가 없으면 종료하는 등의 작업을 수행한다.
Fuzzer 설계
Preprocess (전처리)
전처리 단계는 퍼저가 효율적으로 동작하기 위한 기반 환경을 마련하는 과정으로, 크게 네 가지 주요 작업(Instrumentation, Seed Selection, Seed Trimming, Preparing a Driver Application)으로 나뉜다.
가) Instrumentation
PUT 안에 instrumentation 코드를 삽입해 각 input에 대한 PUT의 실행 흐름이 어디까지 도달 가능 한지를 확인하는 것을 말한다. 즉, 프로그램의 실행 과정을 관찰할 수 있도록 대상 프로그램에 분석용 코드나 모니터링 로직을 삽입하는 과정이다. 퍼징의 효율은 code coverage와 같은 피드백 정보의 정밀성에 크게 의존하므로 핵심적인 절차라 할 수 있다. 수집되는 PUT의 내부 정보의 양에 따라 Black-box, White-box, Gray-box로 fuzz testing의 색이 정해진다. 또한, Instrumentation은 소스 코드 수준, 컴파일러 수준 혹은 바이너리 수준에서 이루어질 수 있다.
Program instrumentation은 static(정적)과 dynamic(동적) 방식으로 나뉘는데 Static 방식은 PUT 실행 전 Preprocess 단계에서 적용되고, dynamic 방식은 실제로 PUT가 실행되는 InputEval 단계에서 적용된다.
■ Static Instrumentaion
주로 소스 코드나 intermediate code에 컴파일할 때 수행된다. 런타임 전에 수행되기 때문에 런타임 오버헤드가 크기 않다는 장점이 있지만 PUT가 라이브러리를 사용한다면 각 라이브러리마다 같은 instrumentation을 적용해야하는 번거로움이 있다. 소스 코드 수준에서 뿐만 아니라 바이너리 수준에서도 Static Instrumentaion이 가능하다.
■ Dynamic instrumentaion
Static Instrumentaion 보다 오버헤드가 심하다는 단점이 있지만 런타임 도중에 이루어지기 때문에 동적으로 링크되는 라이브러리에 쉽게 instrumentation 적용이 가능하다는 장점이 있다.
한 퍼저가 한 가지 이상의 Instrumentation 방법을 사용할 수도 있다. 예를 들어, AFL의 경우 전용 컴파일러로 소스 코드에 static instrumentation을 적용하고 QEMU로 바이너리 수준에서 dynamic instrumentation도 적용한다.
나) Seed Selection
퍼저는 fuzz configuration set을 받아 fuzzing algorithm의 행동을 제어한다. 이때 fuzz configuration의 파라미터들은 value domain(정의역)이 너무 방대하다는 것이 문제다. 즉, 퍼저는 입력 공간이 사실상 무한하기 때문에, 초기 seed pool의 크기 축소 문제(seed selection problem)를 해결하는 것이 탐색 효율을 좌우한다.
seed selection problem을 해결하는 몇 가지 접근 방식과 도구들이 있다. 그중 일반적인 접근 방식은 node coverage 같은 coverage metric를 최대화 할 수 있는 가장 작은 seed set을 찾는 것이다. 이런 과정을 minset 계산이라고 한다.
다) Seed Trimming
seed가 작을수록 메모리는 더 적게 소비하고, 더 높은 throughput을 유도한다. 따라서 어떤 퍼저는 퍼징을 하기 전에 먼저 시드의 크기를 줄인다. 이런 작업을 seed trimming이라고 한다. seed trimming은 PREPROCESS에서 메인 fuzzing loop을 수행하기 전에 수행되거나, CONFUPDATE의 일부분으로 수행된다.
라) Preparing a Driver Application
PUT를 직접 퍼징하는게 어려울 경우 퍼징을 위한 driver 프로그램(PUT이 라이브러리일 때, 라이브러리 속 함수를 호출해주는 중간다리 역할의 프로그램)을 만들 수 있다. 해당 과정은 fuzz campaign을 시작할 때 한 번만 수행되지만, 상당히 번거로운 작업이다. 이는 프로그램이 특정 API를 통해 입력을 받는 경우, 해당 API를 호출하도록 wrapper를 제작하거나 Harness를 구축하는 작업을 포함한다.
Scheduling (스케줄링)
스케줄링은 다음 fuzz iteration을 위해 fuzz configuration을 선택하는 것을 의미하고 각 configuration의 내용은 퍼저의 종류에 따라 다르다.스케줄링의 목적은 현재 이용 가능한 정보들을 통해 최선의 결과를 낼 수 있는 configuration을 정하는 것이다. 즉, 어떤 입력을 우선적으로 변형하고 실행할 것인가를 결정하는 전략적 요소이다.
가) 탐색(Exploration) vs. 활용(Exploitation)의 균형
스케줄링 알고리즘은 최대한 많은 정보를 수집하기 위해 새로운 코드 경로를 탐색할 것인지, 아니면 현재 가장 유리한 결과물로 이어질 것 같은 실행 경로를 심화 분석할 것인지 결정해야 한다. 이러한 문제를 Fuzz configuration Scheduling(FCS) 문제라고 한다.
나) seed의 가중치 부여
각 seed에는 실행 시간, 커버리지 크기, 충돌(crash) 발생 가능성 등 다양한 속성을 기반으로 점수가 부여될 수 있다. 퍼저는 이 점수를 근거로 입력을 선택한다. 예를 들어, AFLFast는 seed의 커버리지 희소성에 따라 스케줄링 우선순위를 동적으로 조정한다.
Input Generation (입력 생성)
test case의 내용이 bug trigger에 직접적인 영향을 미치기 때문에 Input generation은 퍼저의 가장 핵심적인 기능 중 하나로, 어떤 방식으로 새로운 입력을 만들어낼 것인가를 다룬다. 크게 Model-based(Generation-based)와 Model-less(Mutation-based)로 구분된다.
가) Model-based(Generation-based)
PUT의 expected input space를 설명하는 model로부터 test case를 생성한다. 예를 들면 input format을 설명하는 문법이라던가 파일 타입을 지칭하는 magic value 등이 model이 될 수 있다. 즉, 대상 입력의 문법적, 구조적 특성을 이해하고 이를 기반으로 입력을 생성하는 방식이다. 파서(parser)나 프로토콜 명세를 활용하여 구조적으로 유효한 입력을 만들 수 있으며, 특히 복잡한 파일 포맷이나 네트워크 프로토콜 테스트에 효과적이다.
나) Model-less(Mutation-based)
PUT의 input이 되는 seed를 변조해 test case를 생성한다. 즉, seed 입력을 다양한 mutation operators을 통해 수정함으로써 새로운 입력을 생성한다. seed의 일부만을 변조하는 것으로 유효하면서도 crash를 유발하는 비정상적인 값을 포함한 test case를 만들 수 있다. 단순한 바이트 치환, 삽입, 삭제부터 시작해, AFL처럼 coverage feedback을 활용하여 더 의미 있는 변이를 선택하기도 한다.
Input Evaluation (입력 평가)
입력을 생성하고 나면 퍼저는 그 입력으로 PUT를 실행하고 resulting execution으로 무엇을 수행할지 결정하는데, 이 과정을 input evaluation이라고 한다.
가) Bug Oracles
퍼징에 사용되는 canonical security policy는 fatal siganl(예를 들면 segmentation fault, assertion failure 등)이 발생하는 모든 프로그램 실행을 violation으로 정의한다. 메모리로 인해 프로그램의 실행 흐름이 바뀔 수 있기 때문에 이런 policy는 많은 메모리 취약점 여부를 알 수 있다.
나) Execution Optimizations
fuzz iteration 초기에 PUT를 로드하기 위해 매번 새로운 프로세스를 생성해야하는데 이러한 방식은 성능 저하가 클 것 이다. 이런 문제를 해결하기 위해 최신 퍼저들은 반복적인 프로세스 로딩 과정을 건너 뛸 수 있는 기능을 제공한다.
다) Triage
Triage란 정책 위반을 발생시키는 test case를 분석하고 보고하는 과정으로 deduplication, prioritization, test case minimization이라는 3단계로 이루어져있다.
■ Deduplication : 같은 버그를 발생시키는 test case와 output 집합을 없에 정리하는 과정
■ Prioritization : 버그를 발생시키는 test case의 고유성 정도에 따라 순위 매기거나 그룹화하는 과정
■ Test case minimization : testcase에서 crash를 야기하는 부분만을 찾아 좀 더 크기가 작고 간결한 test case를 만드는 과정
Configuration Updating (구성 업데이트)
Configuration Updating은 Black-box, White-box, Gray-box를 구분하는데 중요한 역할을 한다. 앞에서 설명하였듯이 CONFUPDATE 함수는 현재 fuzz run 중에 수집된 configuration 및 실행 정보를 기반으로 configuration set ℂ를 수정할 수 있다. CONFUPDATE의 가장 단순한 형태는 업데이트(수정) 없이 파라미터 ℂ를 그냥 반환하는 형태이다.Black-box fuzzer는 bug oracle인 Obug를 evaluate 하는 것 외에 어떤 프로그램 introspection(프로그램 내부에서 정보 획득)도 수행하지 않는다. 따라서 ℂ를 수정할 정보를 수집하지 않았으므로 일반적으로 ℂ를 업데이트하지 않는다.반대로 Gray-box와 White-box fuzzer의 CONFUPDATE는 더 정교하게 구분되어 새로운 fuzz configuration을 통합하거나 제거할 수 있다. CONFUPDATE는 한 번의 fuzz iteration에서 수집한 정보를 향후 모든 fuzz iteraion에서 사용할 수 있도록 한다. 예를 들어, 화이트 박스 퍼저는 Black/Gray-box fuzzer에 비해 상대적으로 적은 수의 test case를 생성하기 때문에, 일반적으로 생성된 모든 test case에 대해 fuzz configuration을 만든다.
python을 활용한 Fuzzer 구현
지퍼징의 전체적인 흐름과 구조를 보다 명확히 이해하기 위해서 Python으로 작성한 간단한 Fuzzer를 구현하였다. 앞서 언급한 Algorithm 1에서 보았듯이, 퍼징은 원칙적으로 프로그램에 무작위 또는 변형된 입력을 반복적으로 주입하고 그에 따른 비정상 종료(충돌)를 관찰하는 과정이다. 발견된 충돌 사례를 저장하고 입력 변형 전략을 조정하면서 동일한 절차를 반복함으로써 취약점을 탐색한다. 본 구현은 이 기본 원리를 충실히 따르되, 교육적 목적에 맞게 설계·단순화하여 핵심 개념을 직관적으로 보여주는 것을 목표로 한다.
초기화 단계
초기화 단계에서는 사용자는 커맨드라인 인자를 통해 유효한 샘플 파일을 전달하고, 퍼저는 이 파일을 바이트 배열로 읽어들인다.
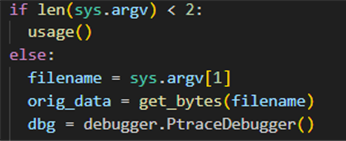
해당 코드는 입력 파일(valid_jpg)이 존재하는지 확인하고, 원본 데이터를 bytearray(get_bytes)로 읽어온 뒤, ptrace(PtraceDebugger()) 기반 디버거를 초기화하여 이후 프로그램 실행 시 발생하는 신호를 감지할 준비를 한다. 이 과정은 논문에서 제시한 Algorithm 1의 PREPROCESS 단계에 해당하지만, 사실상 간단한 초기화(임시·크래시 디렉토리 생성, 원본 샘플 로드)로만 구현되어 있다. 즉, 실행 파일에 대한 계측(instrumentation)이나 시드 속도·유효성 측정 같은 전처리 작업을 수행하지 않는다. 간단하게 입력을 준비하고 실행 환경을 구성하는 기능을 수행한다.
입력 변형 단계
입력 변형 단계에서는 원본 데이터를 기반으로 새로운 test case를 생성한다. 구체적으로 파일 길이의 일부 바이트를 랜덤하게 선택하고, 각 바이트에 대해 비트 플립 또는 매직 값 삽입 중 하나를 무작위로 적용한다.
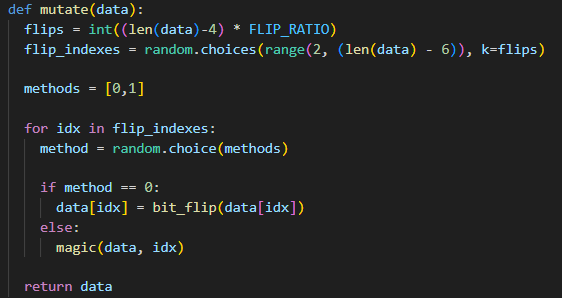
비트 플립은 선택된 바이트의 특정 비트를 토글하여 미세한 변화를 만들며, 매직 값 삽입은 0x00, 0xFF, 0x7F, 0xFFFFFFFF 등 경계값과 특수값을 덮어씀으로써 프로그램의 입력 처리 로직에서 예상치 못한 동작(crash)을 유발한다. 실제로 비트 플립은 다음과 같이 구현되어 있다.

선택된 바이트를 1, 2, 4, 8 등 8가지 비트 패턴 중 하나와 XOR 연산하여 변형한다. 매직 값 삽입 함수는 다음과 같다.
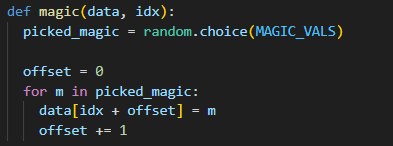
해당 코드에서는 MAGIC_VALS 목록에서 하나를 선택하여 단일 바이트 또는 다중 바이트를 덮어쓰게 된다. 해당 방법들은 메모리 오버플로우·언더플로우 등 취약점 촉발 가능성을 높인다.
그리고 이러한 변형 과정은 Algorithm 1의 INPUTGEN 단계에 해당하며, 해당 코드에서는 입력 구조를 고려하지 않고 랜덤과 휴리스틱 기반으로 test case를 생성한다.
테스트 케이스 저장 단계
생성된 변형 데이터를 파일로 저장하는 과정도 포함되어 있다. 퍼저는 변형된 바이트 배열을 지정된 경로에 파일로 기록하여 대상 프로그램이 이를 입력으로 사용할 수 있게 한다.
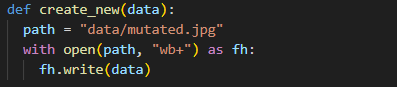
이 과정은 Algorithm 1에서 INPUTGEN 이후 프로그램에 입력을 전달하는 준비 단계로 볼 수 있다.
대상 프로그램 실행 및 충돌 감지 단계
실제 실행 단계에서는 변형된 입력 파일을 대상으로 프로그램을 실행하고, 비정상 종료 여부를 감지한다. 해당 퍼저는 ptrace를 사용하여 대상 프로그램을 자식 프로세스로 실행하고, 실행 도중 발생하는 신호를 관찰한다.
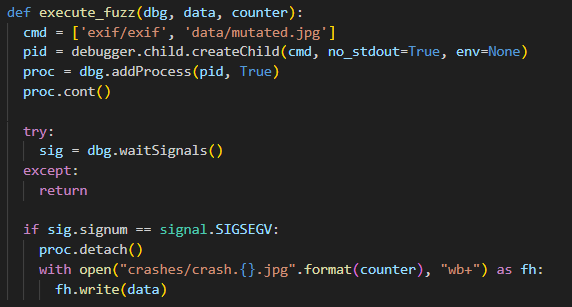
세그멘테이션 폴트(SIGSEGV)가 발생하면 해당 입력을 crashes 폴더에 저장하여 나중에 분석할 수 있도록 한다. 이는 Algorithm 1의 INPUTEVAL 단계에 해당하며, 버그 오라클로 충돌을 판정하고 문제를 재현할 수 있는 데이터를 확보하는 기능을 수행한다. execinfos를 수집하는 기능은 최소화되어 단순 종료 시그널만 활용한다.
반복 루프
퍼징 루프는 지정된 반복 횟수만큼 변형과 실행, 충돌 감지를 계속 수행한다. 해당 코드에서는 10만 번 반복하도록 설정되어 있으며, 반복마다 원본 데이터를 복사하여 변형을 적용하고 실행한 뒤, 100회마다 진행 상황을 출력한다.
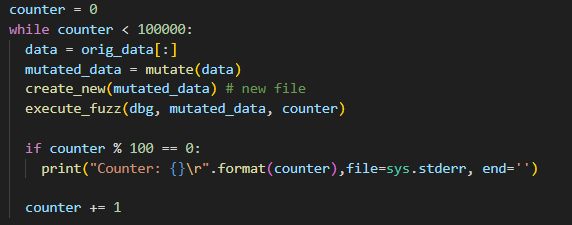
종료 조건은 단순히 반복 횟수로 결정되며, 커버리지나 신규 경로 발견 여부 같은 동적 조건은 반영되지 않는다. 따라서 Algorithm 1의 CONTINUE 단계 중 간단한 반복 제어만 구현된 셈이다. 또한 EXECINFOS를 기반으로 구성 집합을 갱신하거나 시드 우선순위를 조정하는 CONFUPDATE 단계는 생략되어, 입력 선택과 변형이 비적응적(non-adaptive)으로 이루어진다. 또한, 입력으로 단 하나의 원본 파일만 사용하고, 반복 루프에서 항상 동일한 시드(orig_data)를 변형하고 실행하고 있다. 즉, 시드 선택이나 스케줄링 로직이 존재하지 않고, 변형 반복만 수행되므로 SCHEDULE 단계가 생략된 상태이다.
전체 코드
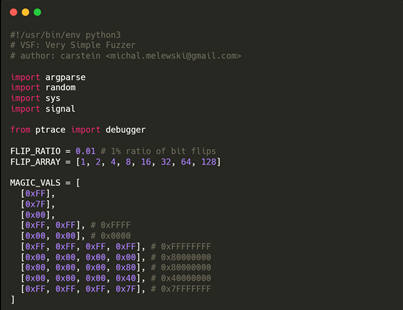
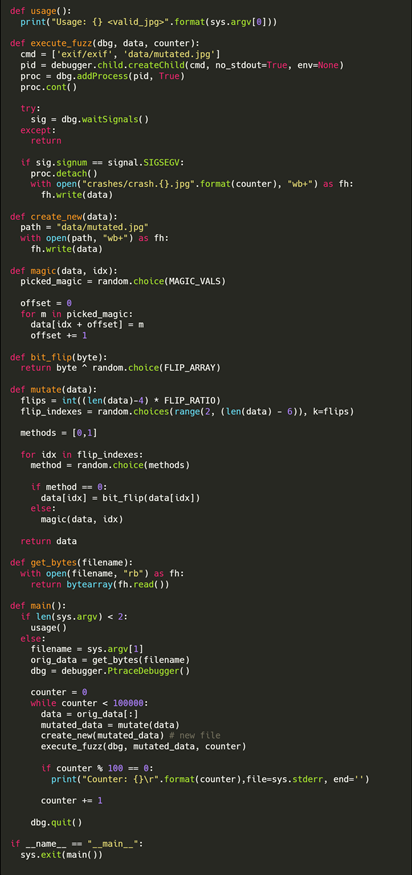
표로 정리하면 다음과 같다.
| 단계 | 구현 함수 / 코드 | 수행 내용 | Algorithm 1 대응 |
|---|---|---|---|
| 초기화 | main(), get_bytes() |
커맨드라인 인자 확인, 입력 파일 읽기, ptrace 디버거 초기화 | PREPROCESS |
| 입력 변형 | mutate(), bit_flip(), magic() |
원본 데이터를 변형하여 테스트케이스 생성. 비트 플립 또는 매직 값 삽입 | INPUTGEN |
| 입력 저장 | create_new() |
변형된 데이터를 파일로 기록하여 대상 프로그램에 입력 | INPUTGEN 일부 |
| 실행 및 충돌 감지 | execute_fuzz() |
대상 프로그램 실행, SIGSEGV 등 비정상 종료 감지, 충돌 입력 저장 | INPUTEVAL |
| 반복 제어 | while counter < 100000 |
지정 횟수만큼 변형-실행-충돌 감지 반복 | CONTINUE |
| 구성 갱신 | 없음 | 입력 선택이나 변형 전략 업데이트 없음 | CONFUPDATE 생략 |
| 시드 스케줄링 | 없음 | 단일 시드만 사용, 시드 선택/우선순위 없음 | SCHEDULE 생략 |
퍼징 실행 결과
다음과 같이 퍼징을 수행하기 위한 폴더를 만들고 코드를 실행한 결과 퍼징 결과 4,366개 크래시가 발생한 것을 확인 할 수 있다.
vsf/
├─ vsf.py → fuzzer 코드
├─ data/
│ ├─ orig.jpg → 시드(원본) 이미지
├─ crashes/ → 퍼징 결과 발생한 crash 파일이 생성될 폴더
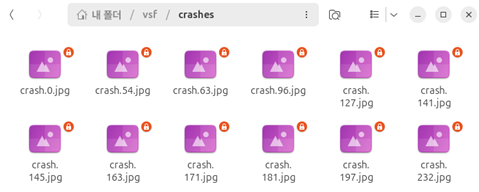
퍼징을 통한 취약점 탐지 및 취약점 분석
지금까지 퍼징의 전체적인 흐름과 구조를 익혔고 이어서 직접 퍼징을 통해 취약점을 탐지하고 탐지된 취약점을 분석해보았다. 본 실습에서는 Fuzzing101의 Exercise 1을 참고하여 AFL++ 퍼징을 수행하였다.
CVE-2019-13288
본 실습에서 분석하는 취약점은 Xpdf 4.01.01 버전의 Parser.cc 파일에 위치한 Parser::getObj() 함수에서 발생하는 취약점이다. 공격자가 특수하게 조작한 PDF 파일을 입력할 경우 해당 함수가 무한 재귀 호출에 빠지게 되며, 이로 인해 프로그램이 정상적으로 종료되지 못하고 서비스 거부(DoS) 상태에 이른다. 이러한 특성 때문에 원격 공격자는 간단한 파일 전달만으로도 Xpdf 기반 서비스의 가용성을 저하시킬 수 있다.
환경 세팅
본격적인 취약점 탐지와 분석을 수행하기에 앞서 실습 환경을 먼저 구축하였다.
VM 다운로드
실습은 Ubuntu 20.04.2 LTS 기반으로 진행되므로, 해당 버전을 가상 머신 환경에 다운로드하여 준비하였다.
https://drive.google.com/file/d/1_m1x-SHcm7Muov2mlmbbt8nkrMYp0Q3K/view
이어서 퍼징 도구를 사용하기 위해서 gcc, pip 등 기본 패키지를 먼저 설치하고 퍼징 대상 환경을 구성하기 위해 프로젝트 디렉터리를 생성한다.
$ sudo apt update -y && sudo apt upgrade -y
$ sudo apt install build-essential gcc -y
$ sudo apt install python3-pip –y
$ cd $HOME
$ mkdir fuzzing_xpdf && cd fuzzing_xpdf/
Xpdf 설치 및 테스트 실행
■ Xpdf 설치 및 빌드
$ wget https://dl.xpdfreader.com/old/xpdf-3.02.tar.gz
$ tar -xvzf xpdf-3.02.tar.gz
$ ./configure --prefix="$HOME/fuzzing_xpdf/install/"
$ make
$ make install
■ Sample PDF 다운로드
$ cd $HOME/fuzzing_xpdf
$ mkdir pdf_examples && cd pdf_examples
$ wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf
$ wget https://www.w3.org/WAI/ER/tests/xhtml/testfiles/resources/pdf/dummy.pdf
–O sample.pdf
$ wget https://www.melbpc.org.au/wp-content/uploads/2017/10/
small-example-pdf-file.pdf
■ pdfinfo 바이너리 테스트
$ $HOME/fuzzing_xpdf/install/bin/pdfinfo –box –meta $HOME/fuzzing_xpdf/pdf_examples/helloworld.pdf
다음과 같이 나오면 성공이다.

- AFL++ 설치
■ 종속 패키지 설치
$ sudo apt-get update
$ sudo apt-get install -y build-essential python3-dev automake git flex bison
libglib2.0-dev libpixman-1-dev python3-setuptools
$ sudo apt-get install -y lld-11 llvm-11 llvm-11-dev clang-11 || sudo apt-get
install -y lld llvm llvm-dev clang
$ sudo apt-get install -y gcc-$(gcc --version|head -n1|sed 's/.* //'|sed
's/\..*//')-plugin-dev libstdc++-$(gcc --version|head -n1|sed 's/.* //'|sed
's/\..*//')-dev
■ AFL++설치
$ cd $HOME
$ git clone https://github.com/AFLplusplus/AFLplusplus && cd AFLplusplus
$ export LLVM_CONFIG="llvm-config-11"
$ make distrib
$ sudo make install
빌드할 때 unicornafl 관련 에러가 발생했지만, 무시하고 진행해도 문제 없다.
■ AFL++ 설치 확인
afl-fuzz를 입력했을 때 다음과 같이 나오면 성공이다.
AFL 컴파일러로 Xpdf 재빌드 및 실행
AFL은 Coverage-guided Fuzzer로 입력 변형을 통해 새로운 실행 경로와 잠재적 버그를 찾기 위해 각 입력의 커버리지 정보를 수집한다. 소스 코드가 있는 경우 AFL은 계측(instrumentation)을 통해 함수나 루프 같은 기본 블록의 시작 지점에 훅을 삽입하여 실행 흐름을 추적할 수 있다. 따라서 대상 프로그램을 퍼징하려면 AFL 전용 컴파일러로 소스 코드를 빌드해 계측을 활성화해야 한다.
■ Xpdf 재빌드 준비
$ rm -r $HOME/fuzzing_xpdf/install
$ cd $HOME/fuzzing_xpdf/xpdf-3.02/
$ make clean
■ afl-clang-fast 컴파일러로 xpdf 빌드
$ export LLVM_CONFIG="llvm-config-11"
$ CC=$HOME/AFLplusplus/afl-clang-fast CXX=$HOME/AFLplusplus/
afl-clang-fast++ ./configure --prefix="$HOME/fuzzing_xpdf/install/"
$ make
$ make install
다. 퍼징 수행
■ 퍼저 실행
$ afl-fuzz -i $HOME/fuzzing_xpdf/pdf_examples/ -o $HOME/fuzzing_xpdf/out/
-s 123 -- $HOME/fuzzing_xpdf/install/bin/pdftotext
@@ $HOME/fuzzing_xpdf/output
i : 입력 파일(Seed)이 있는 디렉터리 경로
o : AFL++ 퍼저가 실행되면서 발생하는 정보를 저장하는 디렉터리 경로
s : 사용할 정적 무작위 시드
@@ : AFL이 생성하는 파일을 @@이 입력된 부분에 input으로 대체
■ 퍼저 실행시 오류
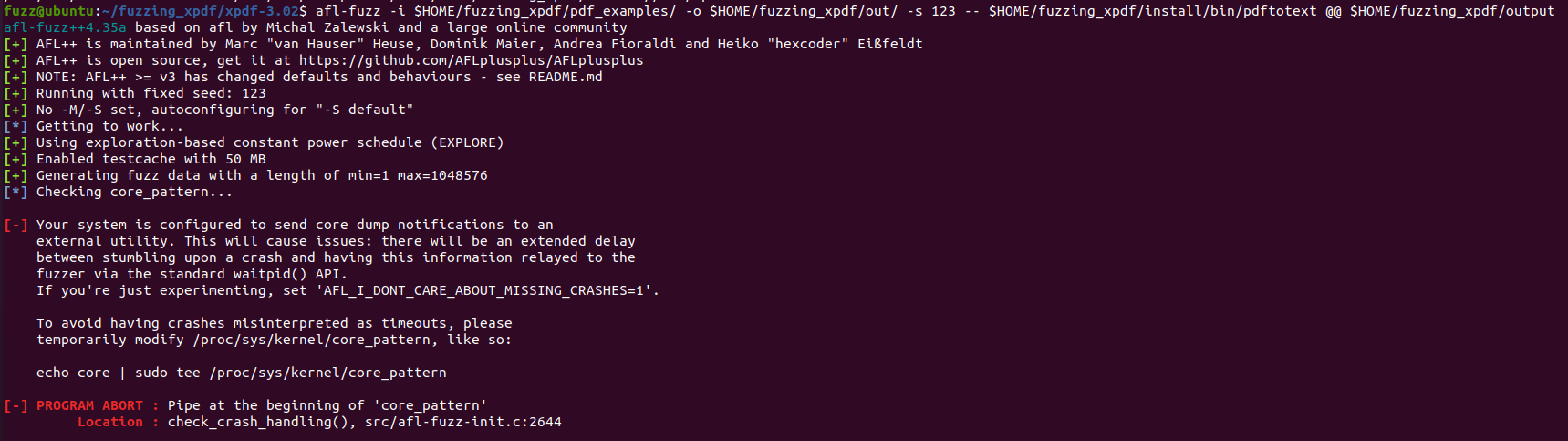
$ echo core | sudo tee /proc/sys/kernel/core_pattern
위와 같은 오류가 발생하면 다음 명령어를 수행하면 된다.
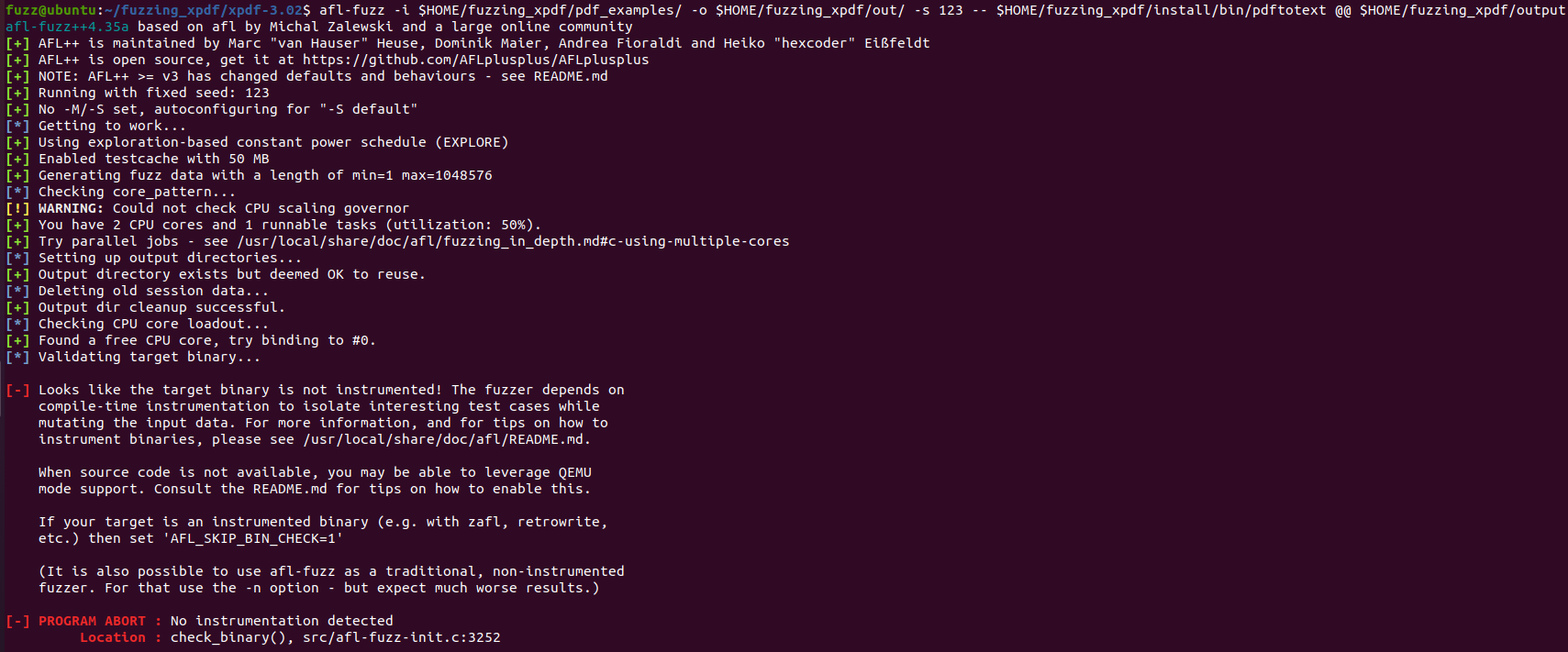
위와 같은 오류가 발생하면 다음 명령어를 수행하면 된다.
# 1. clang 설치
$ cd AFLplusplus
$ sudo apt update
$ sudo apt install clang –y
# 2. apt 업데이트 준비
# sudo apt update
# sudo apt install wget software-properties-common -y
# 3. LLVM 15 repo 추가
$ wget https://apt.llvm.org/llvm.sh
$ chmod +x llvm.sh
$ sudo ./llvm.sh 15
# 4. AFL++ LLVM 모드 빌드
$ export LLVM_CONFIG=/usr/bin/llvm-config-15
$ make clean
$ make distrib
# 5. GCC 모드로 configure 실행
$ cd ~/fuzzing_xpdf/xpdf-3.02
$ export CC=afl-gcc-fast
$ export CXX=afl-g++-fast
$ ./configure —disable-shared --prefix=$HOME/fuzzing_xpdf/install
# 6. 빌드
$ make
$ make install
■ 퍼저 실행 화면
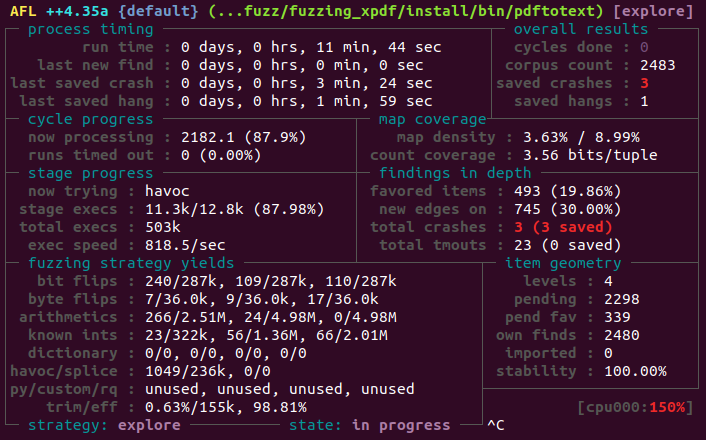
퍼저가 정상적으로 동작하면 위와 같은 화면을 확인할 수 있다. 현재 퍼징은 약 11분 동안 실행했으며, 총 3개의 크래시가 발견되었다.
발생한 크래시 입력 파일들은 설정한 output 디렉터리 아래의 default/crashes 폴더에 저장된다.
크래시 분석
크래시 확인
크래시 파일 이름은 다음과 같다.

이 파일을 아래 명령어를 통해 pdftotext 바이너리의 입력으로 전달한다.
$ $HOME/fuzzing_xpdf/install/bin/pdftotext
$HOME/fuzzing_xpdf/out/default/crashes/<your_filename>
$HOME/fuzzing_xpdf/output
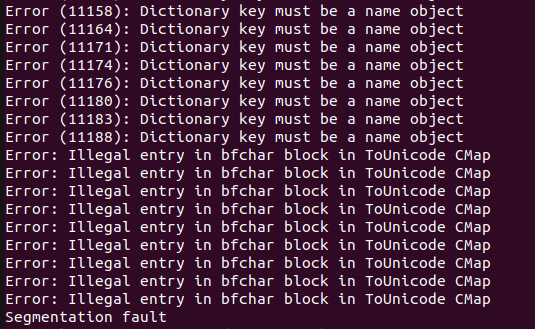
3번째 크래시를 전달하면 다음과 같이 세그먼테이션 오류가 발생하고 프로그램이 충돌하는걸 확인할 수 있다.
gdb로 크래시 분석
gdb를 사용하여 크래시 분석을 수행한다. 분석 시에는 계측(instrumentation) 코드가 불필요하므로 아래 명령어를 통해 Xpdf를 다시 빌드한다.
$ rm -r $HOME/fuzzing_xpdf/install
$ cd $HOME/fuzzing_xpdf/xpdf-3.02/
$ make clean
$ CFLAGS="-g -O0" CXXFLAGS="-g -O0" ./configure —prefix=
"$HOME/fuzzing_xpdf/install/"
$ make
$ make install
이어서 gdb를 실행한다.
$ gdb —args $HOME/fuzzing_xpdf/install/bin/pdftotext
$HOME/fuzzing_xpdf/out/default/crashes/<your_filename>
$HOME/fuzzing_xpdf/output
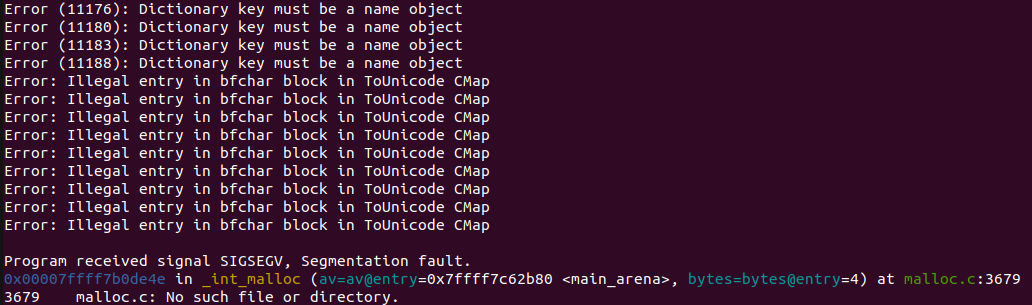
gdb 내부에서 run 명령으로 크래시 지점까지 실행하면 다음과 같이 출력된다.
이후 bt 명령으로 콜 스택을 확인한다.
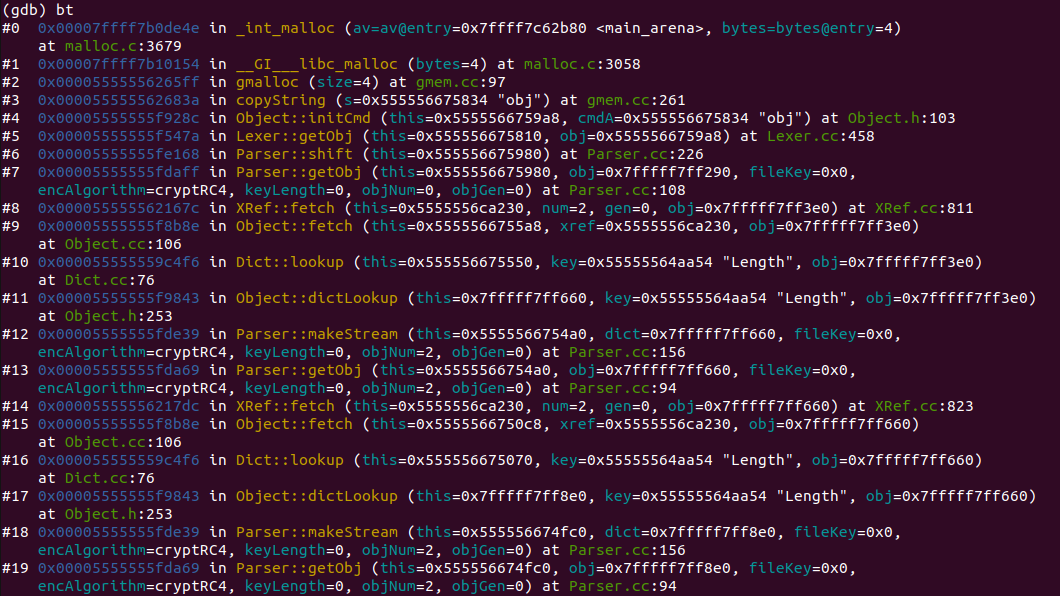
호출 스택을 살펴보면 “Parser::getObj” 메서드 호출이 여러개 나타나는데, 이는 무한 재귀가 발생했음을 의미한다. backtrace를 보면 특정 구간이 반복되는 것을 확인 할 수 있고 해당 부분이 재귀 호출되면서 스택 프레임이 계속 쌓여 크래시가 발생한 것으로 판단할 수 있다.
gdb에서 얻은 backtrace는 CVE-2019-13288의 취약점과 일치한다.
반복되는 코드 구간인 #13부터 #19까지 자세히 살펴보자
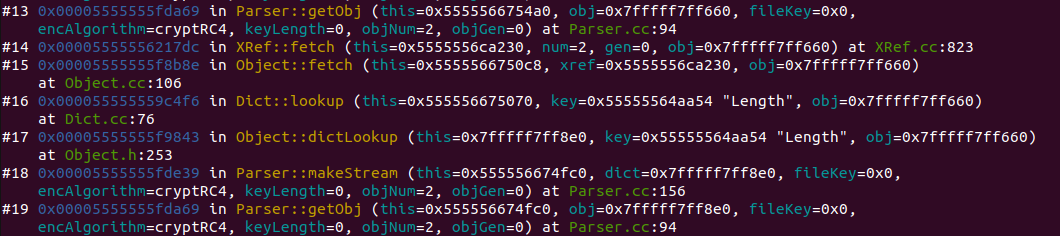
다음과 같은 함수가 반복되는 것을 확인 할 수 있다.
Parser::getObj → Parser::makeStream → Object::dictLookup → Dict::lookup → Object::fetch → XRef::fetch
코드 분석
xpdf 3.04 버전으로 살펴보았다.
■ Parser::getObj (#19)
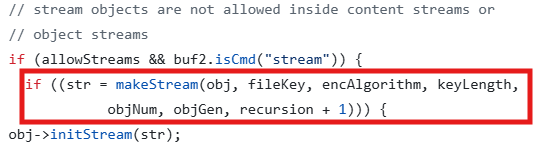
위 코드 부분에서 makeStream 함수를 호출한다. makeStream을 따라가 보자
■ Parser::makeStream (#18)
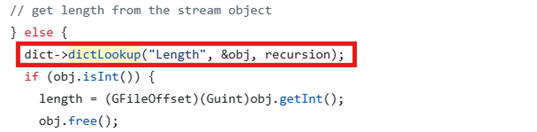
makeStream 함수 안에서 dictLookup 함수가 호출된다. dictLookup도 따라가자
■ Object::dictLookup (#17)

dictLookup 함수안에서 lookup 함수를 호출한다.
■ Dict::lookup (#16)
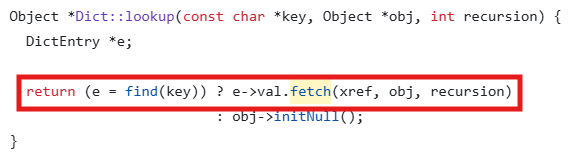
삼항 연산자를 사용해 값을 반환하며, 반환 과정에서 fetch 함수를 호출한다.
■ Object::fetch (#15)

fetch 함수는 객체가 objRef이면 xref를 통해 참조된 실제 객체를 가져오고 있다. fetch를
따라가보자
■ XRef::fetch (#14)
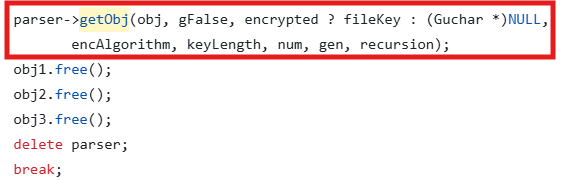
fetch 함수 안에 getObj 함수가 존재한다. getObj를 따라가보자
■ Parser::getObj (#13)
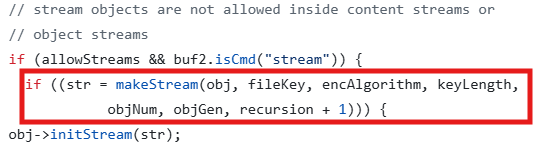
#19부터 backtrace를 따라가 #13까지 도달했는데, #19와 동일한 코드에 다시 도달했다.
실행 시에는 #13부터 #18까지 차례로 호출되고 해당 루틴이 재귀적으로 반복되면서 크래시가 발생한 것을 알 수 있다.
패치
무한 재귀호출을 방지하기위해 패치된 부분을 확인해자
패치 이전 버전 3.02(왼)와 패치된 버전인 4.02(오)를 비교해 보면 다음과 같다.
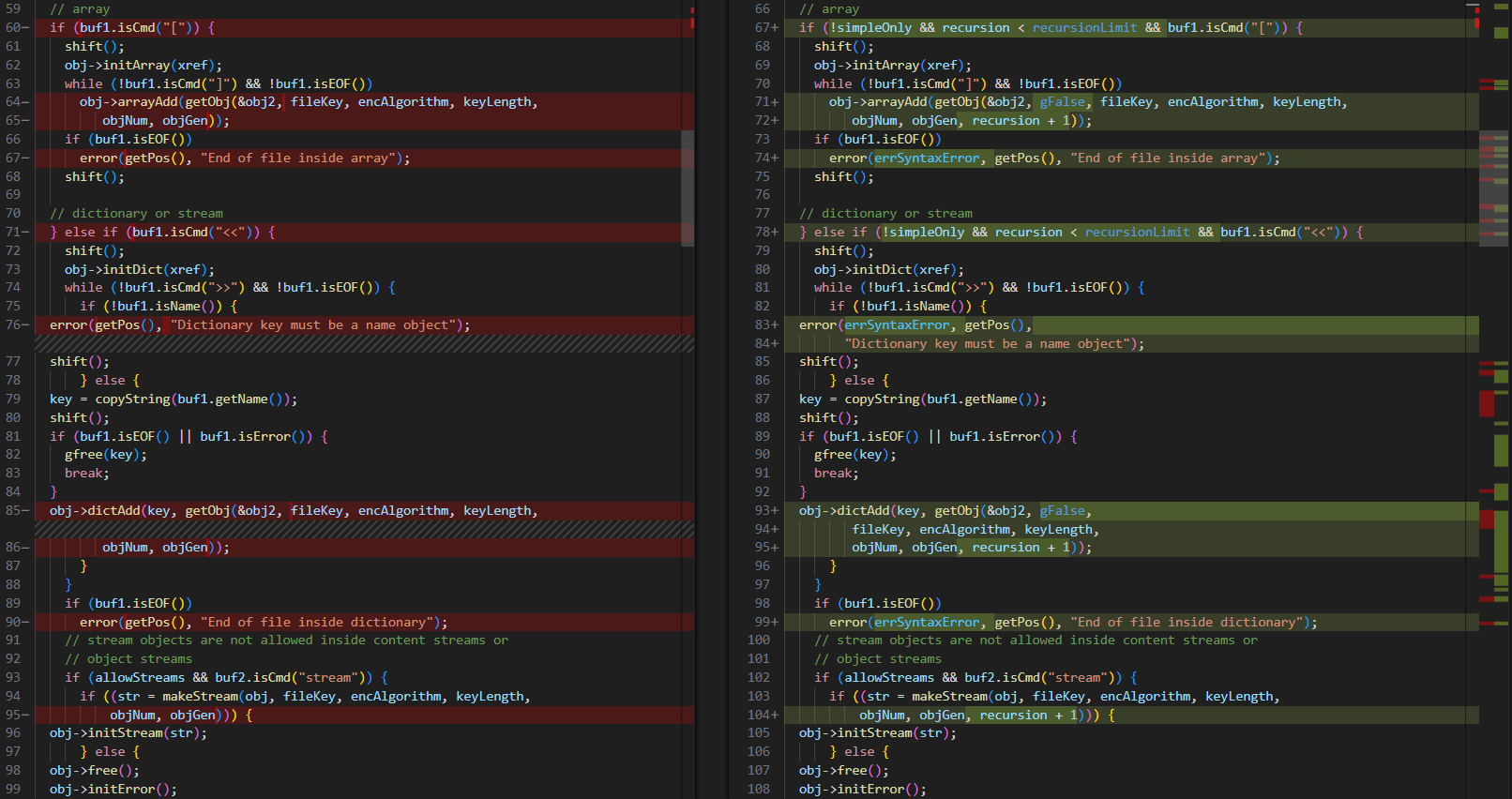
recursion 변수를 추가하여 재귀 호출이 recursionLimit를 초과하면 함수가 더 이상 자기 자신을 호출하지 않도록 제한하였으며, 이를 통해 중첩 오브젝트의 최대 깊이가 설정되어 해당 값을 넘지 않도록 패치되었다.
참고자료
[1] Valentin J.M. Manes, HyungSeok Han, Choongwoo Han, Sang Kil Cha, Manuel Egele, Edward J. Schwartz, Maverick Woo . (2018). The Art, Science, and Engineering of Fuzzing: A Survey.
[2] Fuzzing Like A Caveman . (2020). https://h0mbre.github.io/Fuzzing-Like-A-Caveman/#.
[3] Build simple fuzzer . (2020). https://carstein.github.io/fuzzing/2020/04/18/writing-simple-fuzzer-1.html.
[3] fuzzing101 . (n.d.). https://github.com/antonio-morales/Fuzzing101.