[2025 SWING magazine] GAN (2)
LSGAN 이미지 생성
생성자와 판별자 간의 손실 함수를 최소 제곱 오류로 정의해서 안정적인 학습을 목표로 하는 LSGAN을 이용해서 이미지를 생성하고자 한다.
4-1. 라이브러리 설정
필요한 라이브러리를 임포트해준다. 데이터 처리, 이미지 변환, 모델 학습, 시각화 관련 라이브러리들을 포함했다.
4-2. 이미지 전처리
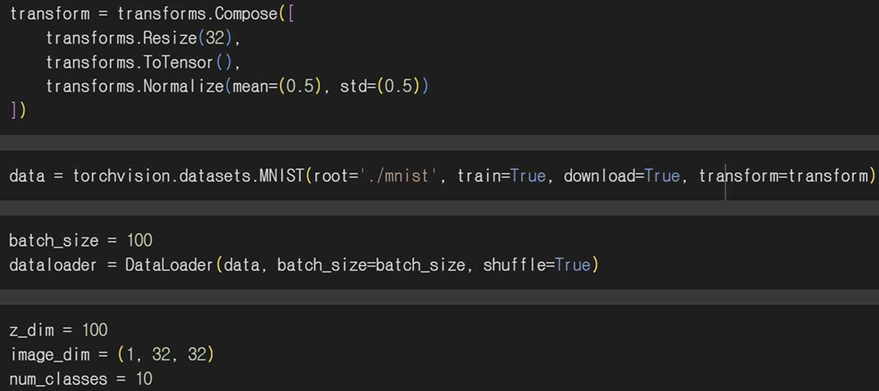
MNIST 데이터셋을 내려받고 이미지를 32x32로 리사이즈한다.
Tensor로 변환하고 정규화해서 데이터로더를 통해 배치 단위로 불러올 수 있게 설정한다.
4-3. 모델 가중치 초기화
생성자와 판별자의 가중치를 정규 분포로 초기화하는 함수를 만들어줘서 모델 학습의 안정성을 높여준다.

4-4. 생성자 정의
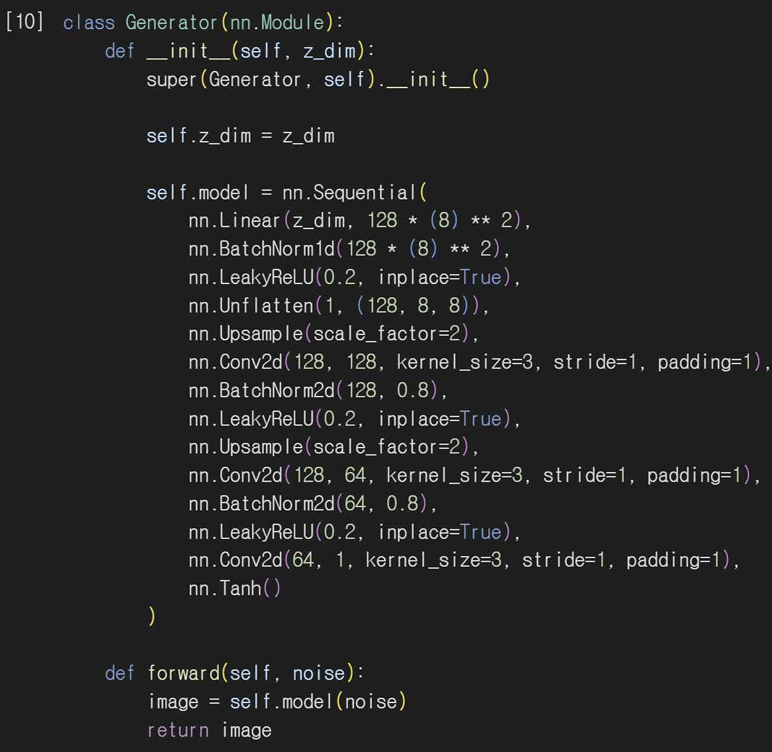
Linear 랜덤 노이즈 벡터인 z_dim을 입력받아서 고차원으로 변환한다. 이 경우 128x8x8차원의 텐서로 변환한다. BatchNormid로 배치 정규화를 해서 내부 공변량 이동을 줄여 학습 안정성을 높인다.
LeakyReLU 비선형 활성화 함수를 사용해주고 Conv2d 합성곱 레이어를 통해 이미지의 세부 특징을 학습해준다. 그리고 Tanh로 출력 이미지의 픽셀값을 [-1,1] 사이로 변환해서 정규화된 입력 이미지에 적합하게 만든다.
4-5. 판별자 정의
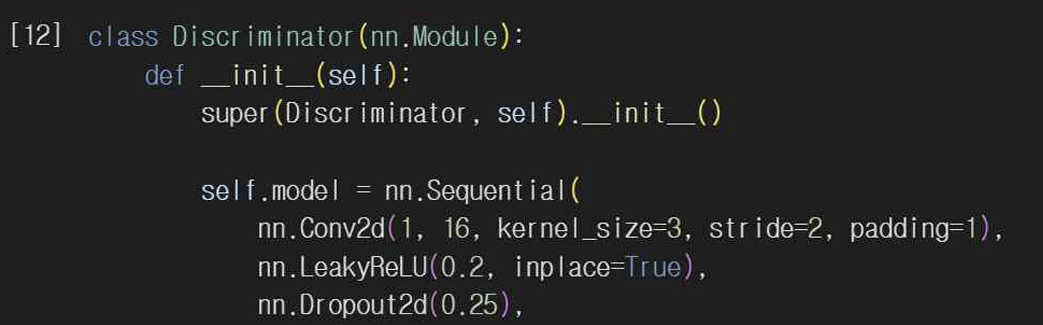
Conv2d로 합성곱 레이어를 사용해서 이미지의 특징을 추출한다. 판별자도 마찬가지로 LeakyReLU 함수를 사용해 비선형성을 추가해서 모델의 표현력을 증가시킨다. Dropout2d를 사용해서 오버피팅을 방지하기 위해 일부 뉴런을 무작위로 비활성화시킨다. 그리고 레이어 출력을 정규화하고 Flatten, Linear를 이용해 1차원으로 변환한 뒤 판별 결과를 출력한다.
4-6. 학습 루프
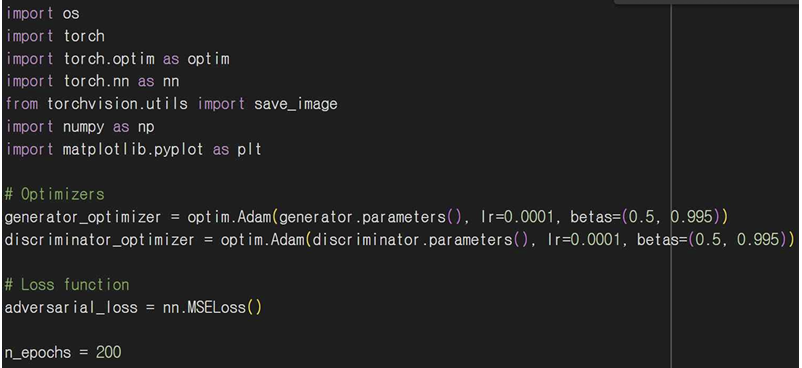
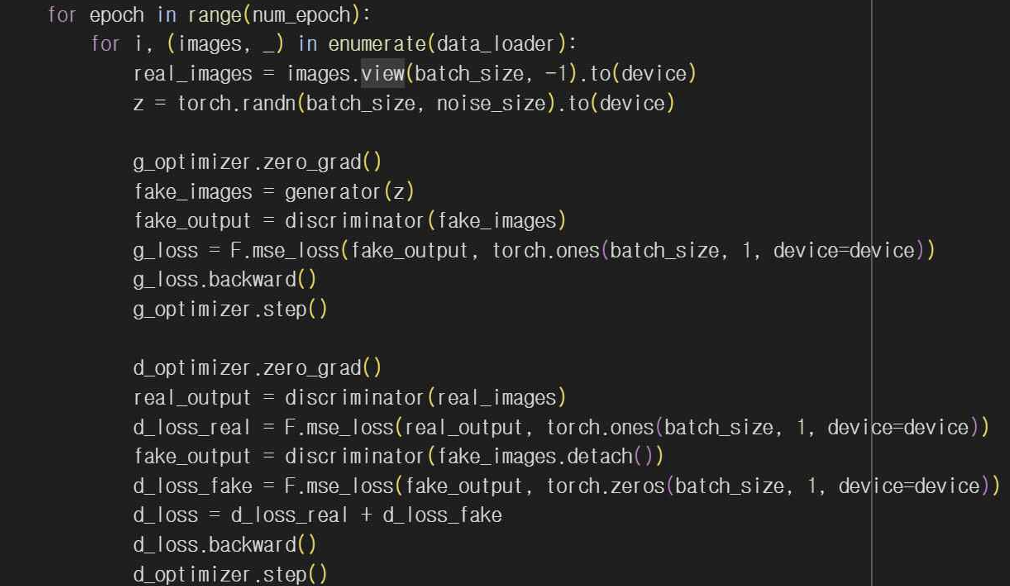
전체 구조로는 학습 루프가 여러 에포크 동안 각 배치에 대해 생성자와 판별자를 번갈아 가며 학습하게 된다. 앞서 기본 GAN, DCGAN의 에포크를 200으로 정해놓았으니 LSGAN도 200만큼 반복하도록 n_epochs를 for 문으로 반복하도록 해줬다. 그리고 Dataloader로 데이터를 배치 단위로 불러와 주고 valid, fake를 사용해 실제 이미지는 1, 가짜 이미지는 0으로 라벨을 생성해준다.
생성자 학습 부분에서 generator_optimizer.zero_grad()로 생성자에 대한 기울기를 초기화해주고 생성자가 사용할 입력인 랜덤 노이즈 벡터 z를 생성해준다. generated_image = generator(z)로 생성자에게 노이즈를 입력해서 가짜 이미지를 생성한다. g_loss로 생성된 이미지가 판별자를 통과한 후의 출력과 valid 레이블을 비교해서 손실을 계산한다. 이때 adversarial_loss는 생성자가 얼마나 잘했는지를 평가하는 지표이다. g_loss.backward() 역전파로 손실을 기반으로 기울기를 계산하여 생성자의 파라미터를 업데이트할 준비를 한다. generator_optimizer.step()으로 계산된 기울기를 사용해 생성자의 가중치를 업데이트해준다.
판별자 학습 부분은 마찬가지로 기울기를 초기화해주고 real_loss와 fake_loss로 실제 이미지, 가짜 이미지 손실을 각각 계산해준다. fake_loss에서 생성된 이미지를 판별자에 통과시켜 가짜 이미지 손실을 계산하게 되는데 여기서 detach()를 이용해 생성된 이미지의 기울기가 판별자에 영향을 주지 않도록 해준다. d_loss로 전체 손실을 계산해주고 backward로 손실 기반 기울기를 계산한 후 가중치를 업데이트한다. 150번째 배치마다 현재 에포크, 스텝, 판별자 손실, 생성자 손실을 출력해서 학습 과정을 모니터링하고 에포크마다 생성된 이미지를 저장해서 reshape를 통해 이미지를 적절한 형태로 변환하고 save_image를 사용해 파일로 저장한 후 각 에포크가 끝나면 출력하도록 해준다.
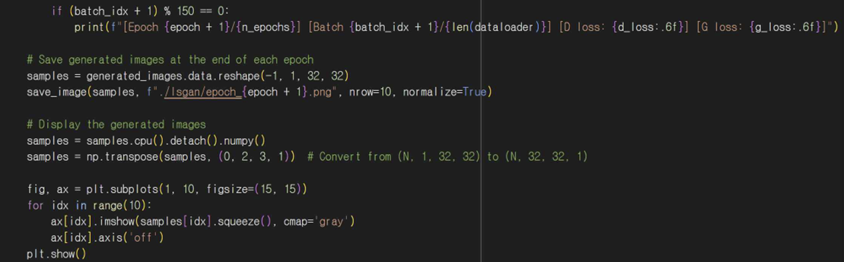
4-7. 생성된 이미지 분석

1 에포크와 200 에포크 상태의 이미지를 비교해보면 1 에포크 땐 테두리가 선명하지 않고 흘러내리는 모습처럼 글씨가 선명하지 않은 걸 확인할 수 있다. 200 에포크 이미지를 확인하면 확실히 1 에포크 때보다 테두리가 선명하고 숫자로 인식할 수 있는 이미지가 생성되었다. 판별자 손실과 생성자 손실을 보면 1 에포크에 비해 200 에포크의 최저 판별자 손실이 더 낮은 걸 확인할 수 있는 반면, 생성자 손실은 비교적 높은 걸 확인할 수 있다.
CGAN 이미지 생성
Conditional GAN은 기존 GAN을 확장해서 특정 조건에 따라 이미지나 데이터를 생성할 수 있도록 만든 모델이다. GAN의 생성자와 판별자에 원하는 조건을 부여해서 생성된 데이터가 특정 조건을 따르도록 훈련한다. 그래서 코드를 작성할 때 기본 GAN 코드를 응용해 작성했다. 기본적인 형태는 기본 GAN과 같아서 CGAN을 구현한 코드와 기본 GAN 코드의 차이점 위주로 설명하고자 한다.
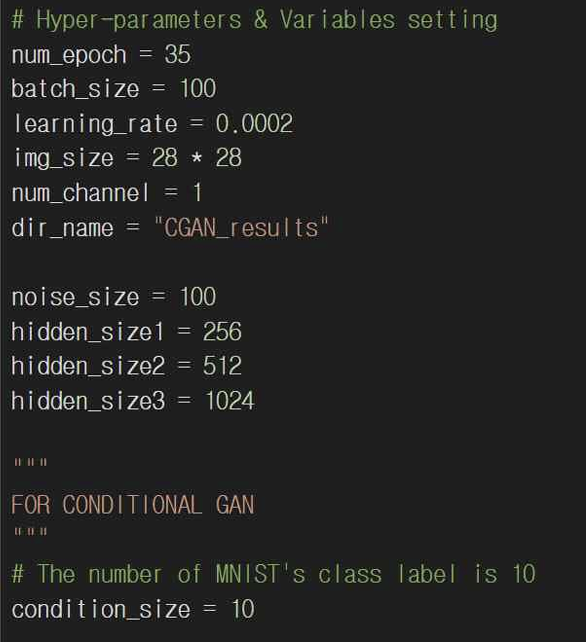
5-1. 조건 인코딩 추가
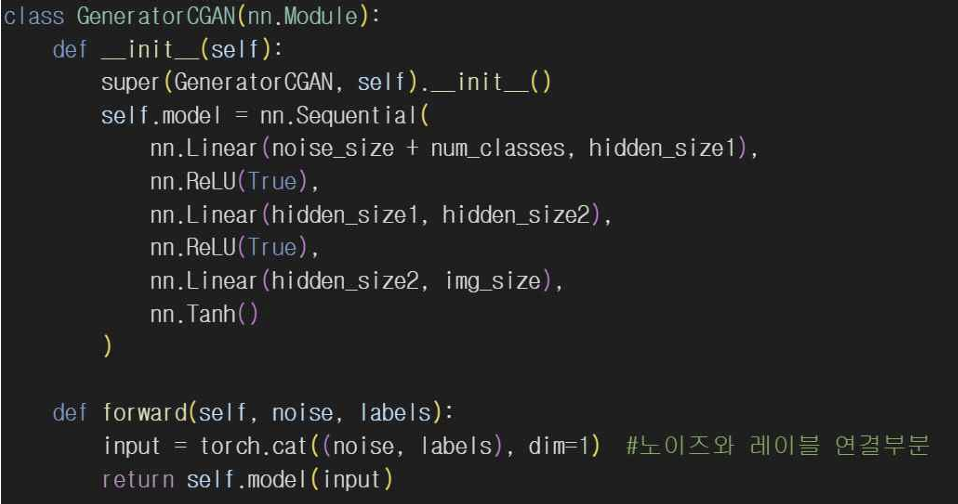
기본 GAN에서는 레이블을 고려하지 않고 노이즈만을 입력으로 사용해서 이미지를 생성하는데 CGAN에서는 특정 클래스(숫자 0~9)로 이미지를 생성할 수 있도록 레이블을 조건으로 사용해준다. 레이블은 원-핫 인코딩(one-hot encoding)해서 이미지 데이터와 함께 네트워크에 입력된다.
5-2. 입력 구조 차이
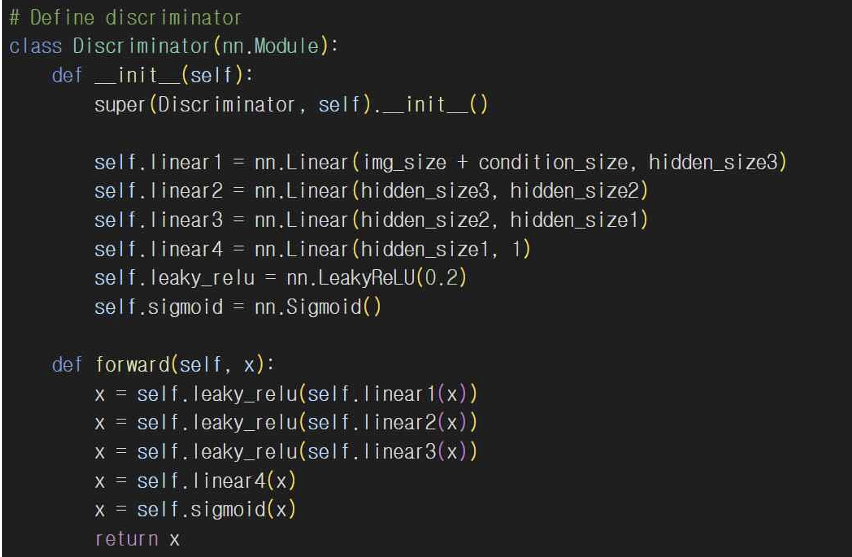
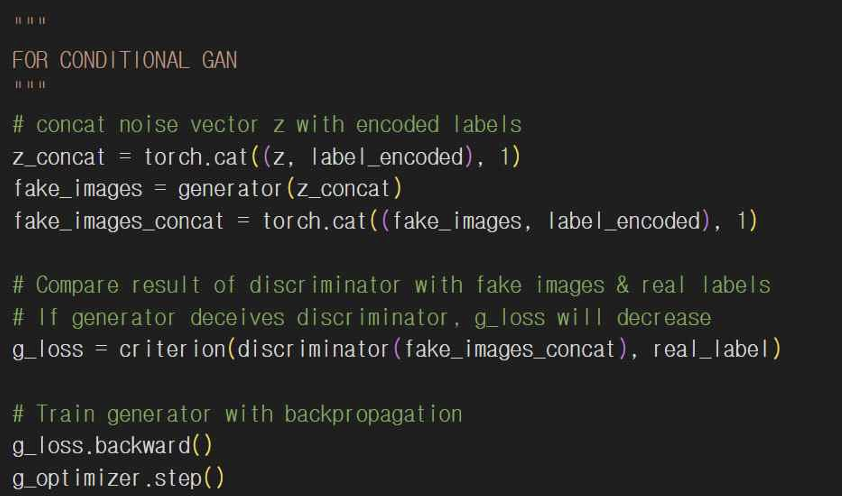
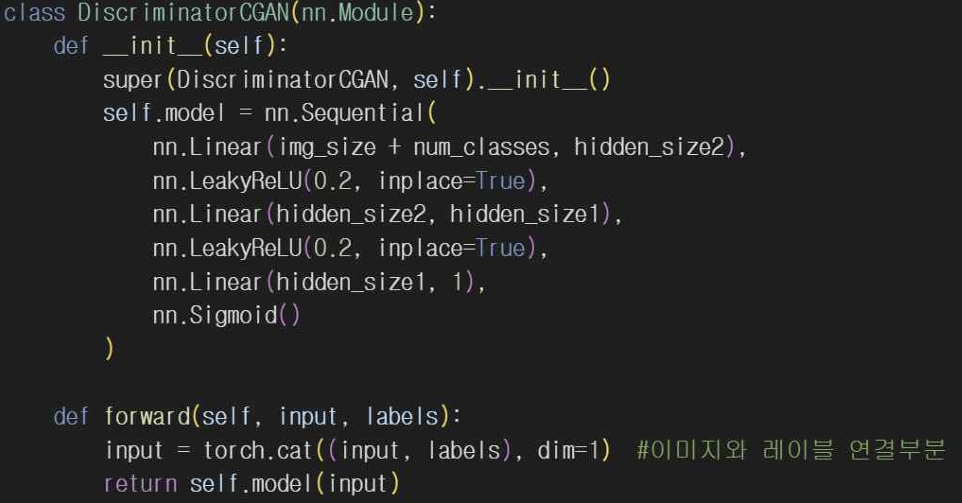
기본 GAN 코드에 레이블 정보가 없어서 생성자와 판별자는 단순히 img_size나 noise_size 형태의 입력을 받게 되고 CGAN은 생성자와 판별자의 입력을 img_size + condition_size나 noise_size + condition_size로 입력받게 된다. 생성자와 판별자 정의도 마찬가지로 CGAN에서 각 레이어에 레이블 정보를 포함해서 학습한다.
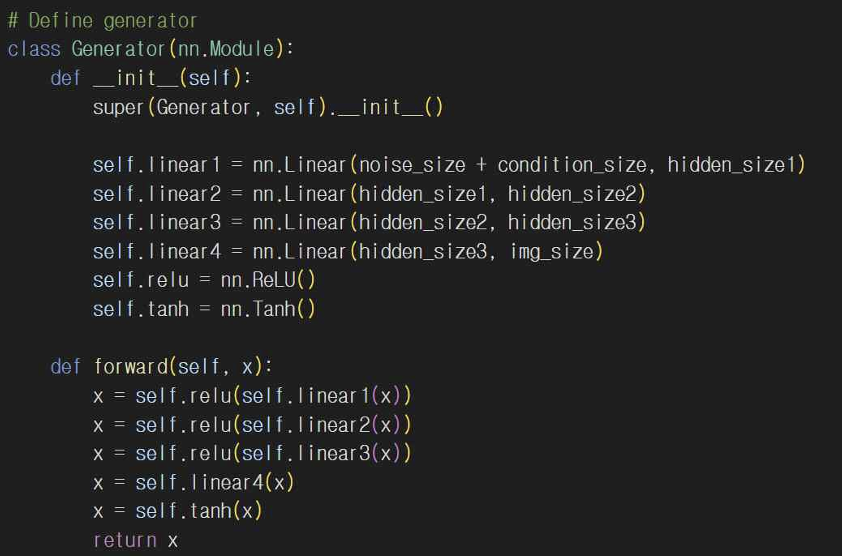
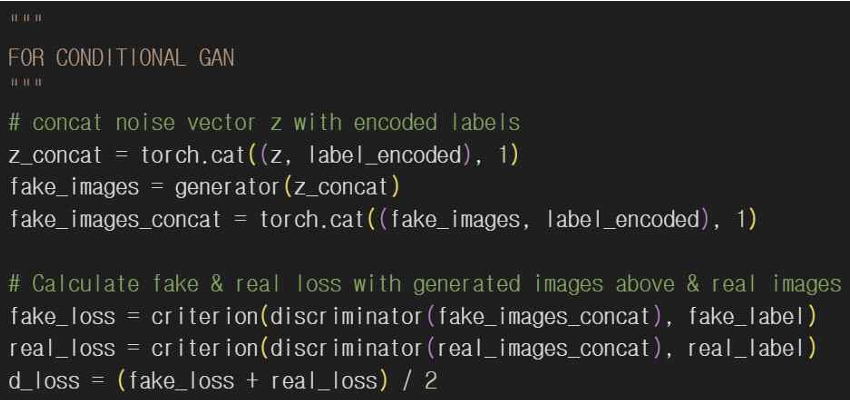
5-3. 조건 체크 함수 유무
레이블이 없는 GAN에는 조건에 따른 이미지 생성 기능이 없고 CGAN에서 학습이 끝난 다음 특정 레이블을 조건으로 설정해서 check_condition() 함수를 통해 조건에 맞는 이미지를 생성하게 된다. 이 함수로 CGAN이 정상적으로 작동하는지 확인할 수 있다.
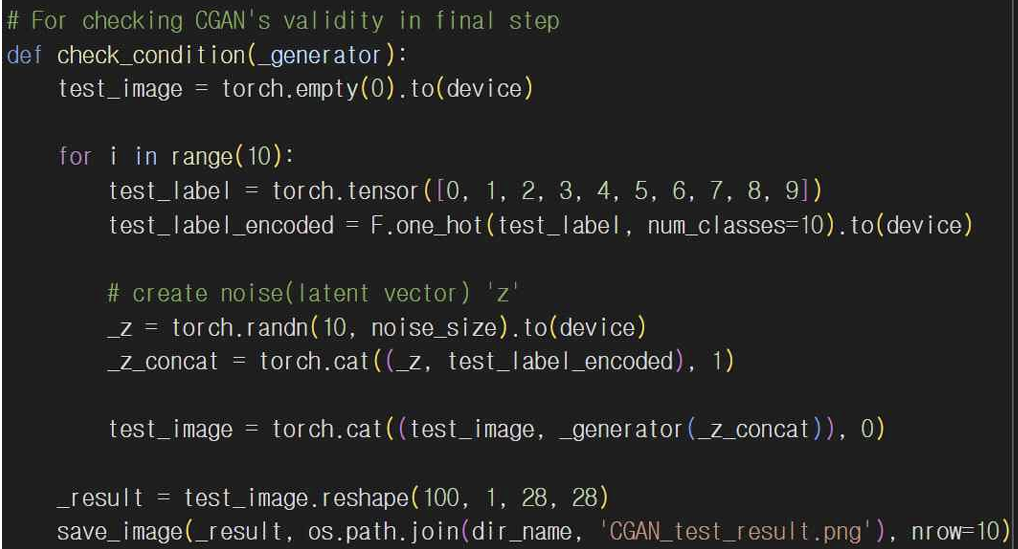
5-4. 생성된 이미지 분석

CGAN 이미지 생성 결과이다. 판별자 손실인 d_loss의 1 에포크 결과를 보면 0.04831에서 100 에포크일 때 d_loss가 0.47632로 작은 차이로 감소한 것을 볼 수 있다. 이는 판별자가 작동을 잘하지 못하고 있다는 걸 의미한다. 생성자 손실인 g_loss를 보면 1 에포크일 때 2.91128이고 100 에포크일 때 1.47756으로 단순히 평면적인 값만 봤을 땐 감소량이 적어보이지만 전체 스텝을 보면 최대가 13.38792이고 100 에포크일 때 최대가 0.91437로 전체적으로 봤을 때 확실히 감소한 모습을 볼 수 있다. 이는 생성자가 더 좋은 이미지를 생성하고 있다는 뜻이다. 그리고 판별자 성능이 0.98로 상대적으로 높은데 이는 생성자가 판별자를 속이는데, 어려움을 겪고 있다는 것을 나타낸다.
각 모델 FID 작성
GAN 모델별 성능을 측정하기 위해 FID 지표를 사용할 것이다. FID 는 Fréchet Inception Distance의 약자로 생성 모델의 성능을 평가하기 위해 많이 사용하는 지표다. FID 는 생성된 이미지와 실제 이미지 분포 차이를 측정해서 생성 모델이 얼마나 현실적인 이미지를 생성하는지 평가한다. FID 값이 낮을수록 생성된 이미지가 실제 데이터와 비슷함을 의미한다.
FID 두 개의 가우시안 분포 간의 거리를 계산하는 방식으로 이루어진다. 동작하기 위해 3가지 과정이 필요하다. 먼저 특징 추출로 생성된 이미지와 실제 이미지를 Inception v3와 같은 신경망에 입력해서 특징 벡터를 추출한다. 여기서 이미지의 임베딩 공간에서 특징을 비교하게 되는데 보통 Inception v3 모델의 마지막 레이어 바로 전의 특징 벡터를 사용한다. 두 번째로 평균과 공분산을 계산하게 된다. 실제 이미지와 생성된 이미지의 특징 벡터에 대해 각각 평균 벡터와 공분산 행렬을 계산한다. 이를 통해 각 이미지 집합의 분포를 표현할 수 있게 된다. 마지막으로 Fréchet 거리를 계산한다. 두 분포의 평균 벡터와 공분산 행렬을 사용해서 다음 공식을 통해 Fréchet 거리를 계산한다.
여기서 μ_real과 μ_fake는 실제 이미지와 생성된 이미지의 평균 벡터를 나타내고 Σ_real과 Σ_fake는 공분산 행렬이다. 다음으로 FID 지표를 계산하기 위해 작성한 코드를 바탕으로 FID 계산이 어떻게 수행되는지 살펴보자.
6-1. GAN FID 코드
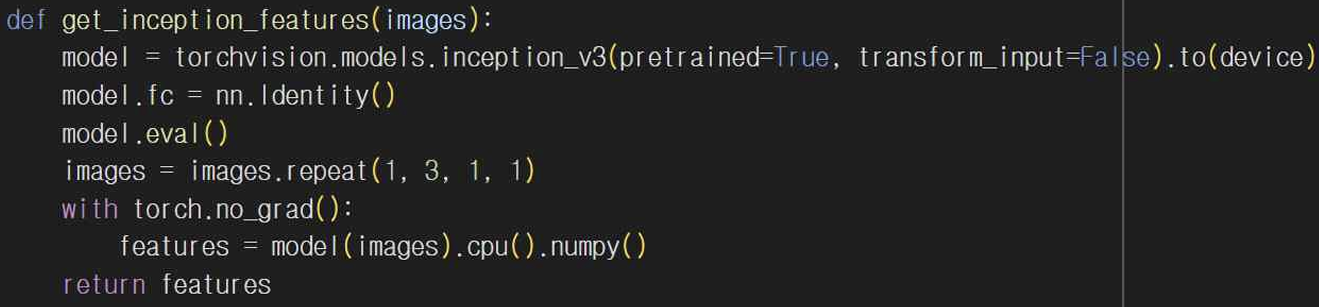
get_inception_features 함수는 Inception v3 모델을 사용해서 이미지를 입력받아 특징 벡터를 추출한다. 이 함수는 torchvision.models에서 사전 학습된 Inception v3 모델을 가져오고 이를 통해 실제 및 생성된 이미지에서 특징을 추출한다.
calculate_fid 함수에서는 추출한 특징 벡터들을 사용해서 실제 이미지와 생성된 이미지의 평균 벡터(mu_real, mu_fake)와 공분산 행렬(sigma_real, sigma_fake)을 계산한다. 그 후 두 분포 간의 Frechet 거리를 계산해서 FID 점수를 반환하게 된다.

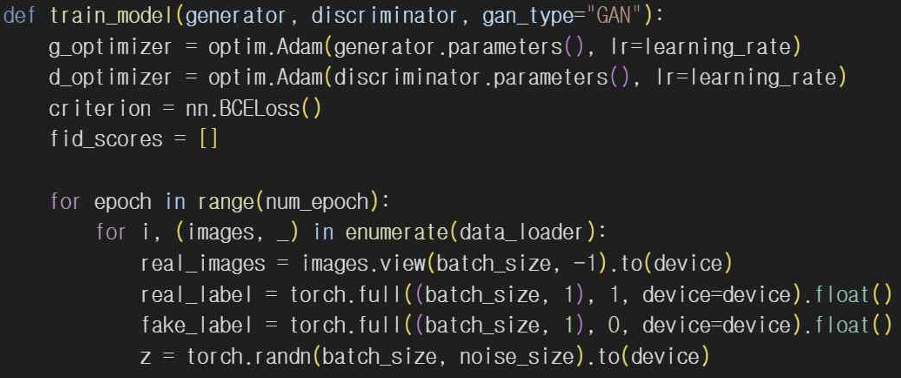
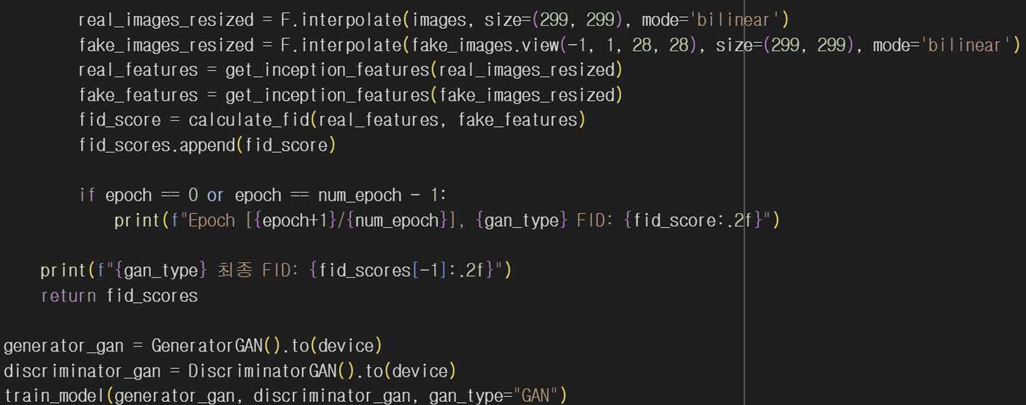
train_model 함수에서 각 에포크가 끝날 때마다 FID를 계산해서 GAN 모델이 학습하는 동안 성능을 평가한다. real_images_resized와 fake_images_resized는 Inception 모델의 입력 크기에 맞게 리사이즈 시키고 get_inception_features를 사용해 각 이미지를 특징 벡터로 변환해줘서 calculate_fid 함수로 두 특징 벡터의 FID 점수를 계산한다. 이렇게 계산된 FID 점수는 fid_scores 리스트에 저장되고 첫번째 에포크와 최종 에포크를 출력해서 결과값을 보여준다.
6-2. DCGAN FID 코드
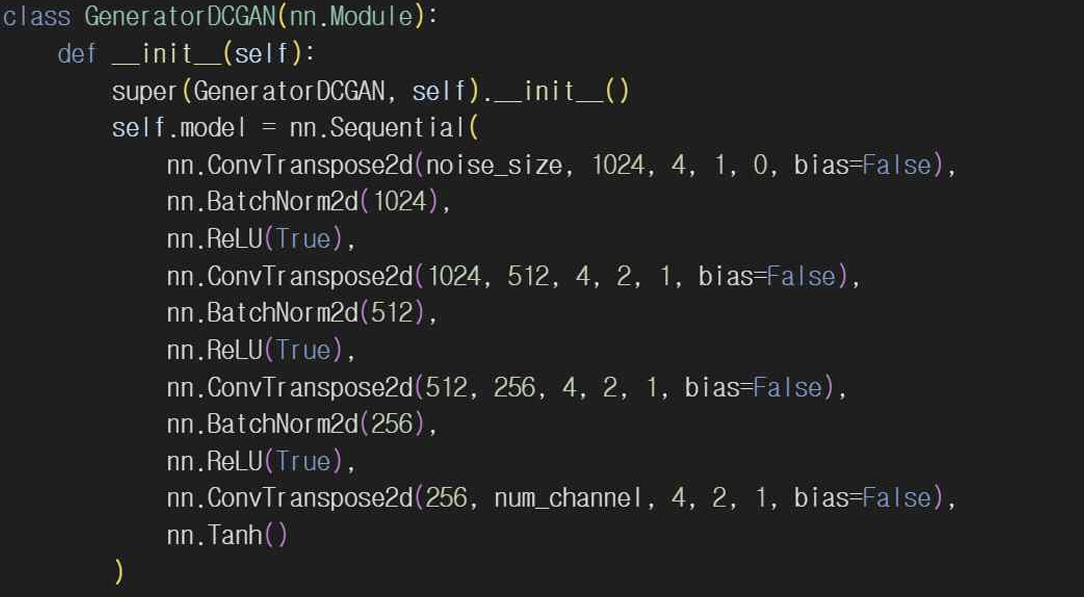
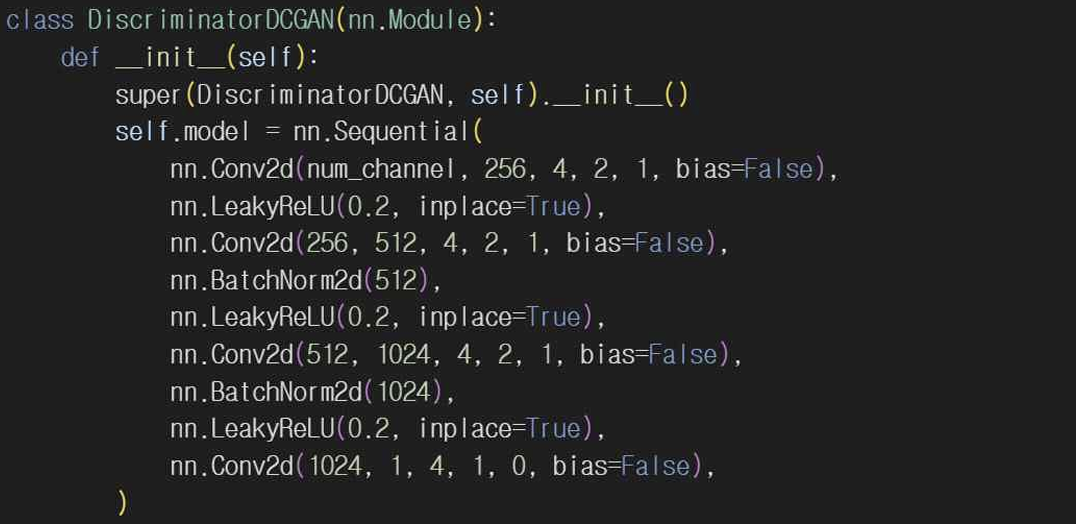
기본 GAN과 달리 DCGAN은 합성곱 층을 사용해서 이미지 생성과 판별을 수행하고 훈련 안정성을 높이기 위해 BatchNormalization과 LeakyReLU를 사용했다.
6-3. LSGAN FID 코드
LSGAN에서는 F.mse_loss를 사용해서 손실을 계산해줬다. 생성자는 판별자로부터 1을 기대하고 판별자는 진짜와 가짜를 1과 0으로 구별하게 된다. LSGAN에서도 판별자 아키텍처는 기본 GAN과 비슷하지만 MSE 손실을 계산하기 위해 마지막 출력 레이어에서 sigmoid 함수를 제거해줬다. 여기서 MSE란 예측값과 실제값 간의 차이를 제곱한 평균값을 계산하는 손실 함수다. LSGAN에서 생성자와 판별자가 훈련할 때 MSE 손실을 사용해서 두 값 간의 차이를 최소화하는 역할로 사용되기도 한다.

6-4. CGAN FID 코드
CGAN은 특정 조건에 대한 이미지를 생성할 수 있도록 설계되어 있어서 원하는 조건에 따라 해당하는 이미지를 생성할 수 있다. 그래서 생성자와 판별자에서 조건 레이블을 입력으로 받아 사용할 수 있도록 수정했고 입력받은 레이블은 원-핫 인코딩을 사용하도록 작성했다. 그리고 생성자와 판별자의 입력으로 노이즈와 레이블을 결합해 사용하고 훈련 중 생성자와 판별자 모두 레이블 정보를 사용할 수 있도록 변경해줬다.
FID 비교 및 정리

먼저 GAN의 FID 결과는 540.90 → 103.69로 총 437.21 차이만큼 낮은 값으로 계산되었다.
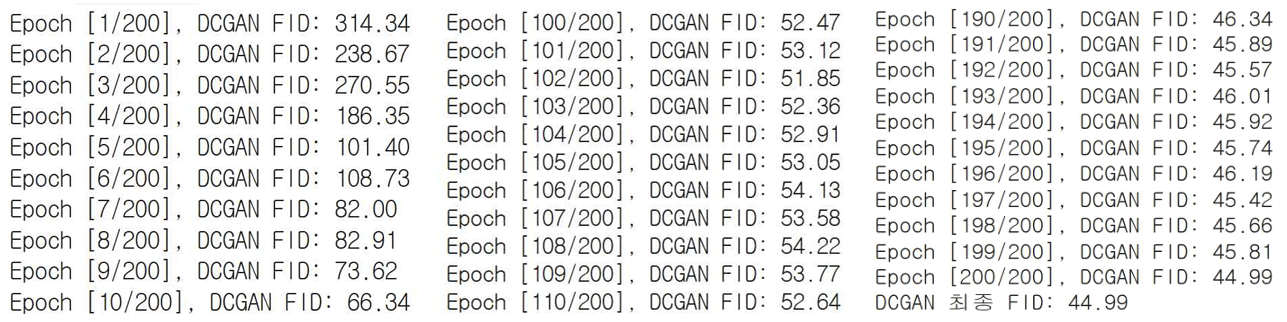
다음은 DCGAN의 FID 결과이다. 314.34 → 44.99로 총 269.35만큼의 차이가 벌어진 값으로 계산되었다.
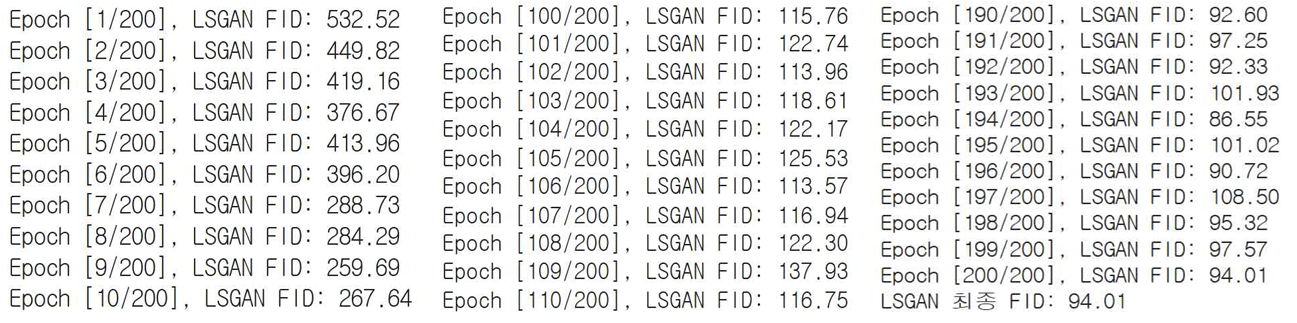
LSGAN의 FID 결과이다. 532.52 → 94.01로 총 438.51만큼 차이가 난 값으로 계산되었다.
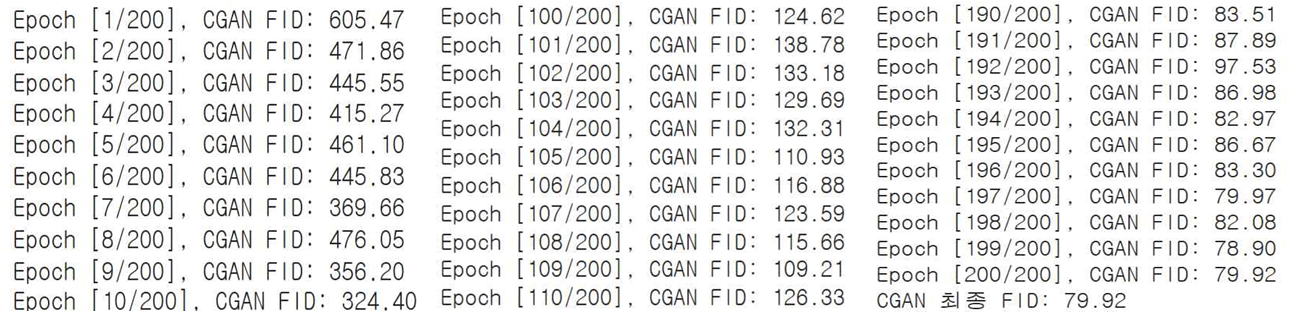
마지막으로 CGAN의 FID 결과이다. 605.47 → 79.92로 총 525.55만큼의 차이가 나는 결과값이 나왔다.
최종 결과값을 놓고 봤을 땐 DCGAN 모델의 값이 제일 낮게 측정되었고 첫 에포크와 마지막 에포크 간의 차이값을 봤을 땐 CGAN 모델의 값의 차이가 가장 컸다.
이번 칼럼에서는 GAN, DCGAN, LSGAN, CGAN 총 네 가지 모델에 대해 알아보고 MNIST 데이터셋을 기반으로 이미지를 생성해보는 실습을 진행했고 각 모델의 성능을 FID 값으로 측정해보았다. 실습을 통해 GAN의 성능은 데이터셋에 따라 달라진다는 것을 알게 되어 생성하고자 하는 이미지의 특성을 고려해 적합한 데이터셋과 GAN 모델을 선정하는 것이 중요하다는 것을 느꼈다. 그리고 학습률, 배치사이즈, 노이즈크기, 에포크 수 등의 파라미터들을 조정해서 각 GAN 모델에 맞는 값을 찾아보는 계기가 되었다. 앞으로도 많은 사람이 원하는 이미지를 생성할 수 있도록 GAN의 발전과 응용에 관한 지속적인 연구가 필요할 것이다. 이를 통해 더 나은 이미지 생성 기술이 개발되고 다양한 분야에서 사용될 수 있기를 바란다.
참고 문헌
Radford, A., Metz, L., & Chintala, S. (2016). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434. https://arxiv.org/abs/1511.06434
Mao, X., Li, Q., Xie, H., Lau, R. Y. K., Wang, Z., & Smolley, S. P. (2017). Least Squares Generative Adversarial Networks. 2017 IEEE International Conference on Computer Vision (ICCV), 2794–2802. https://doi.org/10.1109/ICCV.2017.304
(Preprint: https://arxiv.org/abs/1611.04076)Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784. https://arxiv.org/abs/1411.1784
Godeastone. (n.d.). GAN-torch (GitHub repository). Retrieved September 19, 2025, from https://github.com/godeastone/GAN-torch
Jarikki. (2020, April 20). GAN 기본 개념 정리. Tistory. https://jarikki.tistory.com/26
Kkwong-guin. (2021, July 5). CGAN 개념 설명. Tistory. https://kkwong-guin.tistory.com/151
UntitledTblog. (2021, May 13). DCGAN 학습 과정. Tistory. https://untitledtblog.tistory.com/158
Vimalpillai. (n.d.). Deep convolutional GANs (DCGAN) with MNIST. Kaggle. https://www.kaggle.com/code/vimalpillai/deep-convolutional-gans-or-dcgan-with-mnist
Alperkaraca1. (n.d.). MNIST Least Squares GAN. Kaggle. https://www.kaggle.com/code/alperkaraca1/mnist-least-squares-gan