[2025 SWING magazine] GAN (1)
GAN이란?
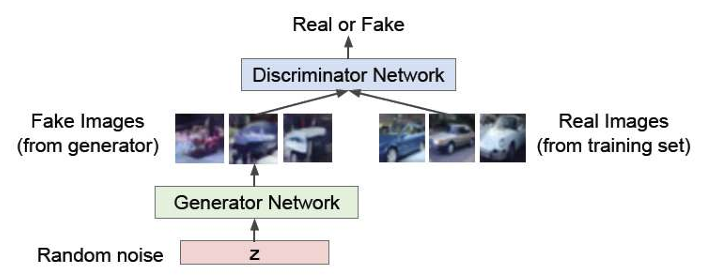
생성적 적대 신경망으로 불리는 GAN은 Generative Adversarial Network의 약자로 두 개의 네트워크,
즉 생성자(Generator)와 판별자(Discriminator)로 구성되고 비지도 학습에 사용되는 머신러닝 프레임워크의 한 종류이다.
생성자는 최대한 실제처럼 보이는 데이터를 생성함으로써 판별자를 속이려 하고, 판별자는 실제 데이터와 만들어진 데이터를 구별한다. 생성자와 판별자가 상호 경쟁하며 학습을 진행한다. 이 과정에서 판별자는 실제 데이터와 만들어진 데이터를 잘 구별할 수 있게 되고 생성자는 실제 데이터와 흡사한 데이터를 잘 생성하게 된다.
GAN의 구조 및 학습 과정은 실제 데이터셋을 준비해서 판별자가 학습하는 데 사용되고 생성자는 이 데이터셋과 비슷한 분포를 따라 랜덤한 노이즈 벡터를 입력으로 받아서 가짜 데이터를 생성하게 된다. 이렇게 생성자가 만든 가짜 데이터를 판별자에게 입력하고 입력한 데이터가 실제 데이터인지 가짜 데이터인지 판단하기 위해 판별자의 손실 함수로 실제 데이터는 1, 가짜 데이터는 0로 예측하는 능력을 측정한다.
GAN의 손실 함수는 생성자와 판별자의 경쟁을 수학적으로 표현한다. 기본 손실 함수는 다음과 같이 정의된다.
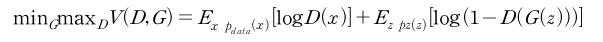
여기서 G는 생성자, D는 판별자, pdata(x)는 실제 데이터 분포, pz(z)는 생성자가 입력으로 받는 노이즈 분포, E는 기댓값을 나타낸다. 이 함수는 두 부분으로 나뉜다. 판별자 손실 부분인 Ex∼p data(x)[logD(x)]는 실제 데이터 x에 대해 D(x)가 1에 가까워지도록 하고 가짜 데이터라고 판단되면 0을 반환한다. 따라서 판별자의 성능이 좋을수록 좌변의 값은 증가하게 될 것이다. 생성자 손실 부분인 Ez∼pz(z)[log(1−D(G(z)))]는 생성된 데이터 G(z)에 대해 D(G(z))가 0에 가까워지도록 한다.
1-1. GAN 이미지 생성
GAN을 실제로 구현하기 위해 pytorch로 구현한 코드를 분석해가며 실행하면서 이해해봤다.
1-2. 라이브러리 및 하이퍼 파라미터 설정
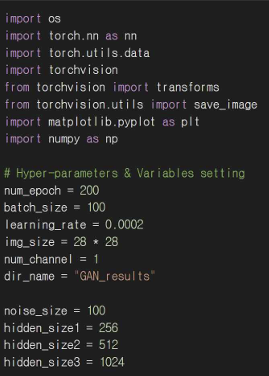
이미지 처리, 데이터셋 로드, 모델 정의 및 학습을 위한 라이브러리를 불러온다. 학습할 횟수( num_epoch), 배치 크기(batch_size), 학습률(learning_rate) 등 학습에 필요한 하이퍼 파라미터와 변수들을 설정하고 이미지 크기, 채널 수, 저장 폴더, 생성자에 입력되는 노이즈 벡터 크기, 각 레이어의 뉴런 수 등을 정의해준다.
1-3. 장치 설정 및 디렉토리 생성
GPU 사용이 가능한지 확인하는 코드로 가능하면 GPU를, 그렇지 않다면 CPU를 사용하도록 설정한다. 생성된 이미지를 저장할 디렉토리를 os.makedirs()로 생성한다.
1-4. 데이터셋 로드 및 전처리 과정
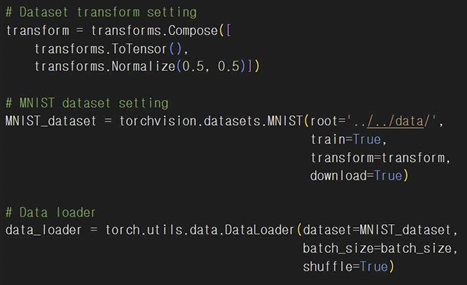
데이터 전처리를 위해 transforms.Compose를 사용해 이미지 데이터를 텐서로 변환하고 [0, 1] 범위를 가지는 이미지를 [-1, 1]로 정규화한다. 이미지를 텐서로 변환해야 사용한 파이토치 모델이 처리할 수 있기 때문이다. 입력 데이터 범위가 [-1, 1]로 고르게 분포되면 네트워크의 가중치가 균등하게 학습되기 때문에 정규화는 필수적이다. torchvision.datasets.MNIST를 사용하여 MNIST 데이터셋을 가져온다.
MNIST는 손글씨 숫자(0-9)의 이미지로 구성된 데이터셋이다. 각 이미지는 28x28픽셀 크기이고 머신 러닝과 딥러닝 모델의 성능을 측정하는 데 자주 사용되는 표준 데이터 셋이다. data_loader를 사용하여 데이터셋을 배치 단위로 불러오고 데이터를 섞는다. GAN이 MNIST 데이터셋을 효과적으로 학습할 수 있도록 준비하는 과정이다.
1-5. 판별자 정의
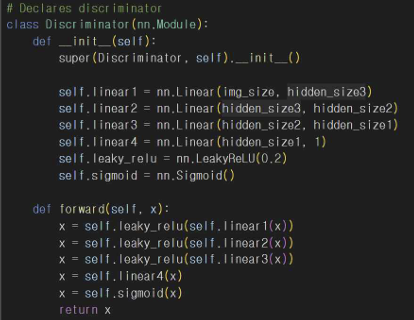
nn.Linear 레이어를 통해 이미지 데이터를 점진적으로 압축해 나가며 활성화 함수를 사용해 비선형성을 추가한다. 마지막 레이어에서 출력값을 [0, 1] 범위로 변환한다. 이때 1은 진짜 이미지, 0은 가짜 이미지를 나타낸다.
여러 층의 신경망을 통해 입력된 이미지를 처리하고 최종적으로 이미지가 진짜일 확률을 출력하게 된다.
1-6. 생성자 정의
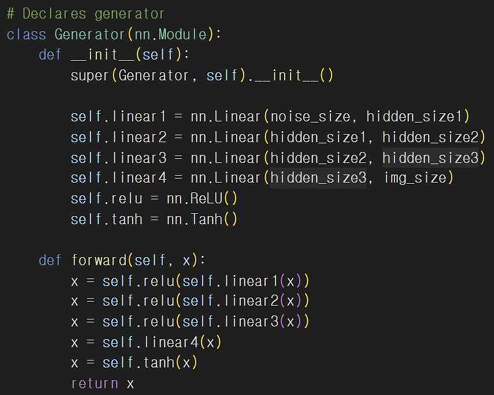
생성자도 마찬가지로 nn.Linear 레이어를 사용하여 판별자와 동일하게 활성화 함수를 사용하고 마지막 레이어에서 출력값을 [-1, 1] 범위로 변환한다. 랜덤한 노이즈 벡터를 입력받아서 이를 기반으로 가짜 이미지를 생성하게 된다.
1-7. 모델 초기화 및 설정
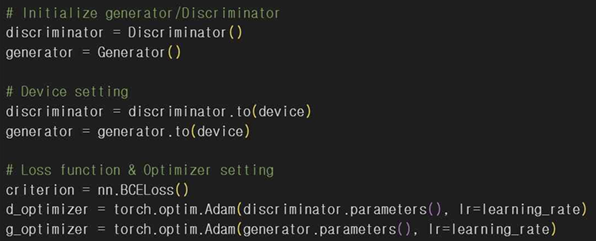
먼저 생성자와 판별자 모델을 초기화 해주고 .to(device)로 판별자 모델을 GPU 또는 CPU로 전송한다. 생성자 모델도 판별자 모델과 같은 디바이스로 전송하게 되고 criterion = nn.BCELoss() 손실 함수로 판별자가 출력하는 확률을 기반으로 손실을 계산한다. 판별자 모델의 파라미터를 계속 업데이트하기 위해 Adam 옵티마이저를 사용하고 학습률로 모델의 파라미터가 업데이트되는 속도를 조절한다. 생성자 모델도 마찬가지로 Adam 옵티마이저를 사용한다.
1-8. 모델 학습
이 구간은 GAN을 학습시킨다. 학습 과정에서 생성자와 판별자가 번갈아 가며 학습하고 판별자는 실제 이미지와 가짜 이미지를 구별하는 능력을 강화하고, 생성자는 점점 더 진짜 같은 이미지를 생성하도록 학습한다.
1-9. 학습 결과물

코랩을 사용해 코드를 실행하면 이렇게 로그 메시지가 뜨면서 이미지가 생성된다. GAN 훈련 중에 특정 에포크와 단계에서 판별자 손실인 d_loss와 생성자 손실인 g_loss를 나타낸다.
Epoch [ 0/200 ] Step [ 150/600 ] d_loss : 0.01995 g_loss : 3.66807 가 제일 처음 결과인데 현재 훈련이 0번째 에포크 진행 중임을 의미한다. 이때 에포크는 전체 데이터셋에 대해 모델이 한 번 학습을 완료한 주기를 뜻한다. 그리고 현재 에포크 내에서 150번째 스텝 진행 중이고 이때 스텝은 배치 단위로 데이터를 처리하는 반복 횟수이다. 판별자 손실인 d_loss가 0.01995임을 나타내 는데 이 값은 판별자가 실제 이미지와 가짜 이미지를 얼마나 잘 구분하는지에 대한 손실을 나타내고 있다. 손실 값이 낮을수록 판별자가 더 잘 구분하고 있음을 의미한다. 생성자 손실인 g_loss는 3.66807로 나타나는데 이 값은 생성자가 판별자를 속여서 가짜 이미지를 진짜 이미지처럼 보이게 만들려는 목표에 대한 손실을 나타낸다. 손실 값이 낮아질수록 생성자가 판별자를 속여 진짜처럼 보이게 하는 데 더 성공적으로 학습되고 있음을 의미한다. 이러한 에포크가 200번째까지 반복하면서 이미지를 생성해나간다.

절반인 100번째 에포크를 보면 d_loss는 높아졌고 g_loss는 낮아지고 생성된 이미지가 처음보다 선명해진 걸 확인할 수 있다.
200번째 에포크는 출력되지 않고 199번째까지만 출력되었는데, 로그 메시지를 확인해보면
Epoch 199’s discriminator performance : 0.71 generator performance : 0.32 이렇게 출력됐다. 판별자와 생성자의 성능을 최종적으로 나타내는 값인데 판별자의 성능은 0.71, 생성자의 성능은 0.32로 판별자가 71%의 확률로 이미지를 올바르게 분류하고 있고 생성자는 32%의 확률로 판별자를 속이는 데 성공한다는 의미를 가지고 있다. 최종적으로 생성된 이미지를 보면 맨눈으로 봐도 0-9까지의 숫자 형태가 정확히 나오지 않고 중복된 숫자나 외곽선이 흐릿한 이미지가 많은 걸 확인할 수 있다.
현재 훈련된 모델에서는 판별자가 우위를 점하고 있다고 로그 메시지를 통해 알 수 있는데 판별자가 생성자가 만든 가짜 이미지를 잘 구분하고 있으므로 생성자가 더 많은 학습을 통해 진짜 같은 이미지를 생성할 수 있도록 개선될 필요가 있다.
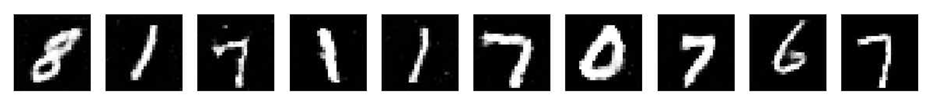
GAN 모델 종류와 발전
기본 GAN은 가장 단순한 형태로 생성자와 판별자가 서로 경쟁하는 형태로 구성되어 있다. 생성자는 무작위 노이즈 벡터를 입력으로 받아 가짜 데이터를 생성하고, 판별자는 이 데이터가 진짜인지 판별하는 역할을 한다. 이러한 GAN은 이미지 생성과 변환, 텍스트 생성 등 다양한 분야에서 응용되어왔다. 그러나 기본 GAN은 초기 모델로서 학습 불안정성의 문제를 겪는 사례가 종종 발생했다. 이러한 문제를 해결하기 위해 다양한 종류의 GAN 모델들이 제안되었으며 각 모델은 특정 문제를 해결하고 생성 능력을 향상하기 위한 새로운 접근 방식을 도입했다는 특징이 있다.
이번 칼럼에서 다룰 GAN 종류는 DCGAN, LSGAN, CGAN 총 3개다.
먼저 DCGAN은 Deep Convolutional GAN으로 딥러닝 모델인 컨볼루션 신경망(CNN)을 사용해서 GAN의 학습 안정성을 개선한 모델이다. 컨볼루션 신경망(CNN)은 사람의 시각 처리 방식을 모방한 딥러닝 학습 모델 이다. DCGAN은 CNN의 컨볼루션 레이어를 사용해서 이미지의 공간적 구조를 보존하면서 해상도를 점진적으로 줄이거나 늘릴 수 있다.
2016년에 발표된 DCGAN에 대한 논문인 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks에서 테스트 데이터로 침실 사진, 사람 얼굴을 주고 에포크의 차이를 두고 DCGAN을 학습시키는 실험을 했다.

1 에포크를 학습시켰을 때의 결과물이다. 멀리서 보면 그럴싸한 침실 사진이겠지만 자세히 보면 흐릿하고 사진이 깨져있는 걸 확인할 수 있다.
하지만 첫 에포크 만에 이미지를 외워서 그대로 내보내지 않고 이미지를 스스로 만들어냈다는 것을 보여주는 결과다.

5 에포크를 학습시킨 결과물은 다음과 같다. 언뜻 보기에도 확실히 선명해진 것을 확인할 수 있고 실제로 존재하는 방처럼 이미지를 만들어냈다. 논문에서는 아직 모델이 학습 오류를 줄이지 못하는 상황인 언더피팅(underfitting)이 일어나고 있다고 말하면서 그 증거로 침대의 머리 부분에 약간의 노이즈가 반복되는 것을 확인할 수 있다고 한다. 이를 통해 DCGAN은 생성자와 판별자가 더 복잡한 이미지 패턴을 학습할 수 있는 능력을 키워준다고 볼 수 있다. 특히 얼굴, 동물, 풍경 등의 이미지 생성에서 뛰어난 성능을 발휘한다.
LSGAN은 Least Squares GAN으로 최소 제곱 오차 손실을 사용해서 최소 제곱 GAN이라고 불린다. 주요 특징으로는 먼저 손실 함수의 변경이 있다. LSGAN은 GAN의 손실 함수로 최소 제곱 오차를 사용해서 판별자가 생성된 샘플에 대해 더 부드러운 순간변화율을 제공해서 생성자에게 더 유용한 학습 신호를 제공해 생성된 데이터가 판별자의 결정 경계에서 벗어나는 것을 방지해준다.
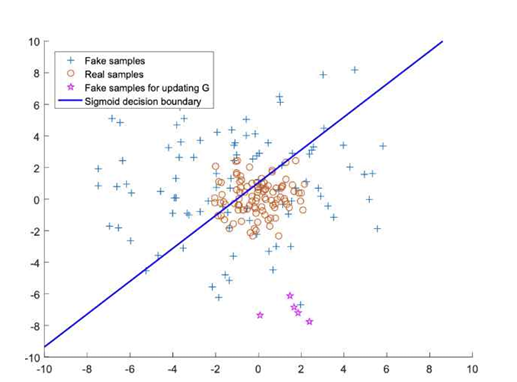
위 그림은 손실 함수를 0과 1로 판단하는 기준을 가지고 있는 파란 선으로 나타낸 그림이다. 파란 선을 기준으로 위는 가짜, 아래는 진짜로 판단한다. + 모양은 가짜 데이터, 주황색 동그라미는 진짜 데이터, 별은 가짜 데이터지만 진짜로 분류된 것들을 나타낸다.
별을 보면 생성자가 판별자를 잘 속이고 있다는 걸 볼 수 있지만, 판별자를 속이는 것에서 끝나는 것이 아니라 사람이 봤을 때도 실제 데이터와 비슷하도록 최대한으로 만드는 것이 궁극적인 목표라고 볼 수 있다. 이걸 인지하고 봤을 때 별은 실제 데이터인 주황색 동그라미와 많이 떨어져 있다. 둘 사이의 거리가 가까울수록 사람까지 속일 수 있다는 뜻인데 이를 이루기 위해 적용한 것이 최소 제곱이다.
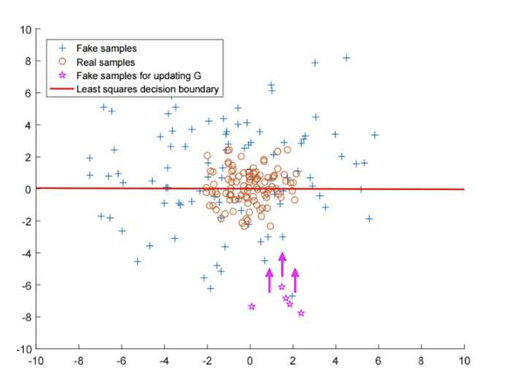
최소 제곱 기준선인 빨간 선이 추가된 모습이다. 이 기준선이 생겨서 별들은 주황색 동그라미와 멀리 떨어져 있을수록 페널티를 받아서 점점 주황색 동그라미와 가까워진다. 그래서 최소 제곱을 GAN에 적용하게 되면 가짜 데이터가 판별자를 속일 정도로 정교해지면서 실제 데이터와 확실히 비슷해지는 효과가 있다.

LSGAN 학습 실험 결과를 보면 DCGAN과 비교할 수 있는데 구조는 거의 동일하게 진행하고 손실 함수만 다르게 조정해서 학습시킨 결과물을 보면 LSGAN의 결과물이 훨씬 선명하고 진짜 존재하는 것 같은 방 이미지를 생성한 것을 확인할 수 있다.
CGAN은 Conditional GAN으로 조건부 GAN이다. 기본 GAN의 확장으로, 생성자와 판별자가 데이터를 생성하거나 판별할 때 추가적인 조건을 고려하는 모델이다. 지금까지 본 GAN 들은 학습한 이미지와 유사한 사실적인 이미지를 생성할 수 있었지만, 이미지의 유형을 제어할 수 없었는데 이 문제를 해결한 것이 CGAN이다. 일반적인 GAN과의 차이점은 생성자와 판별자 모두 조건 정보를 입력으로 받는다는 것이다.
이 조건 정보는 특정 숫자 클래스, 이미지 속성 등 다양하고 생성자는 이 조건을 바탕으로 특정한 특성을 가진 데이터를 생성하게 된다. CGAN은 주어진 조건에 따라 데이터를 생성할 수 있으므로 멀티모달 데이터의 상관관계를 학습하는 데 효과적이다. 아래의 사진은 CGAN을 멀티모달 데이터에 적용한 예시이다. 텍스트-이미지 변환으로 텍스트 설명을 조건으로 제공하고 이에 해당하는 이미지를 생성하는 작업이다. 텍스트를 임베딩해서 생성자의 입력으로 사용하고 그 텍스트 임베딩을 기반으로 이미지 특성을 조절한다. 여기서 임베딩이란 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자 나열인 벡터로 바꾼 결과나 과정 전체를 의미한다.
DCGAN 이미지 생성
DCGAN의 주요 특징으로 다양한 Layers를 사용하여 이미지를 처리해서 이미지의 공간적 구조를 유지하면서 더 효과적으로 특징을 추출하고 생성한다. kaggle에서 코드를 참고해 코랩에서 실행해봤다.
3-1. 라이브러리 설정
3-2. 데이터 준비
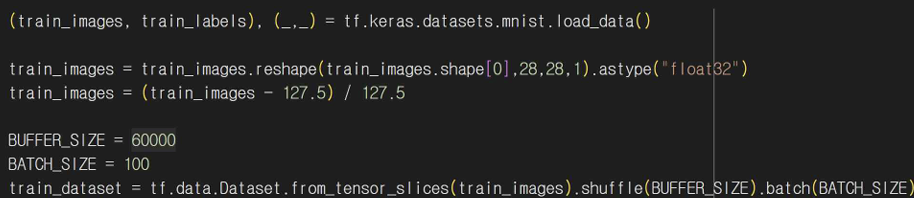
MNIST 데이터셋을 로드하고 데이터 전처리를 해주기 위해 이미지를 (28, 28, 1) 형태로 변형하고 픽셀값을 [-1, 1] 범위로 정규화한다. tf.data.Dataset을 사용하여 데이터셋을 생성하고 무작위로 섞은 후 배치 처리를 한다.
3-3. 생성기 모델 정의
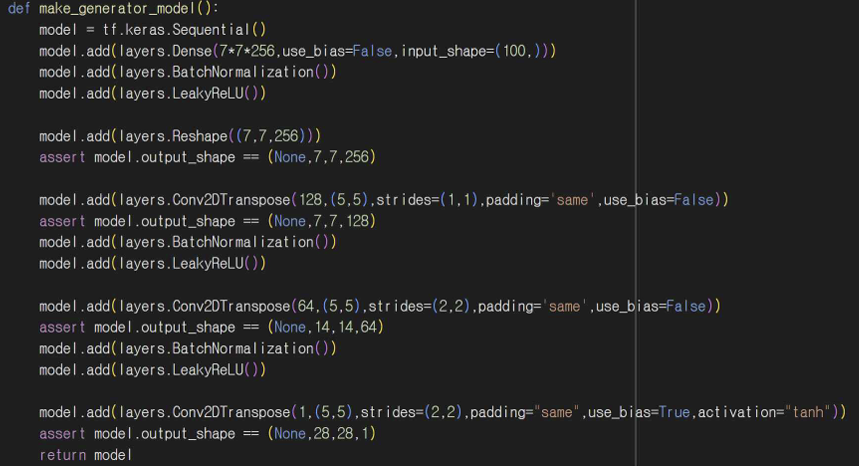
Dense Layer를 사용해서 입력된 노이즈를 통해 7x7x256 크기의 텐서로 변환한다. 이 레이어는 생성 과정에 첫 단계로 낮은 차원의 노이즈를 고차원 텐서로 확장해주는 역할을 한다. BatchNormalization과 LeakyReLU 함수로 학습 안정성을 높이고 비선형성을 추가해서 더 복잡한 패턴을 학습할 수 있도록 해준다. Conv2DTranspose 업샘플링 레이어를 사용해서 텐서를 더 큰 차원인 28 * 28 크기의 이미지로 생성하게 한다. Tanh Activation으로 출력 이미지를 -1에서 1 사이로 변환해서 정규화된 이미지 데이터와 일치하도록 만들어준다.
3-4. 판별자 모델 정의
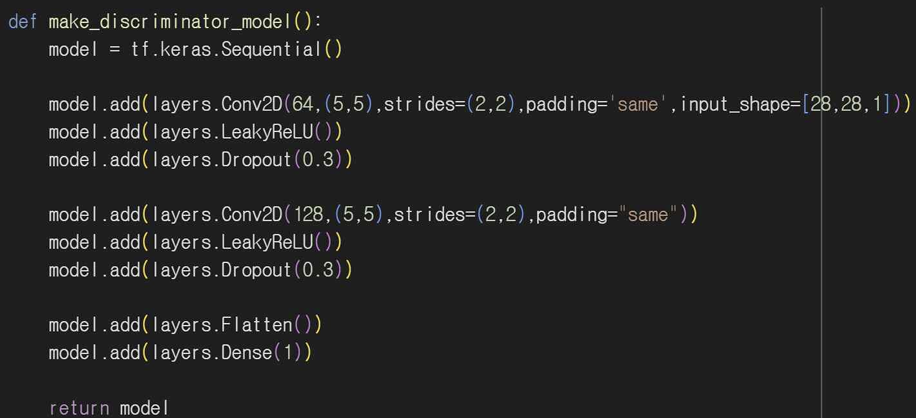
Conv2D로 이미지를 다운샘플링하여 특징을 추출한다. 생성자 모델처럼 LeakyReLU 함수를 사용해 더 복잡한 패턴을 학습할 수 있게 하고 Dropout 함수로 모델이 과적합되지 않도록 방지한다.
Flatten과 Dense로 최종적으로 1개의 값을 출력하여 이미지가 실제인지 판별하게 된다.
3-5. 손실 함수와 옵티마이저
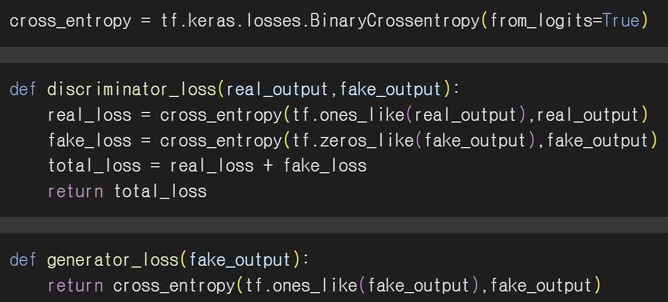
BinaryCrossentropy 이진 분류 손실 함수로, 판별자가 실제 이미지를 1로 예측하고 가짜 이미지를 0으로 정확히 예측하도록 학습한다. Discriminator Loss로 판별자의 손실을 계산한다. 실제 이미지에 대해 1의 레이블을 사용하고 가짜 이미지에 대해 0의 레이블을 사용해서 손실을 계산해준다. Generator Loss로 생성자는 가짜 이미지를 실제처럼 보이도록 만드는 손실을 계산한다. 생성자는 판별자가 가짜 이미지를 1로 예측하도록 학습한다.

Adam Optimizer를 생성자와 판별자 모두 적용해서 파라미터를 업데이트한다.
3-6. 체크포인트와 이미지 생성 함수
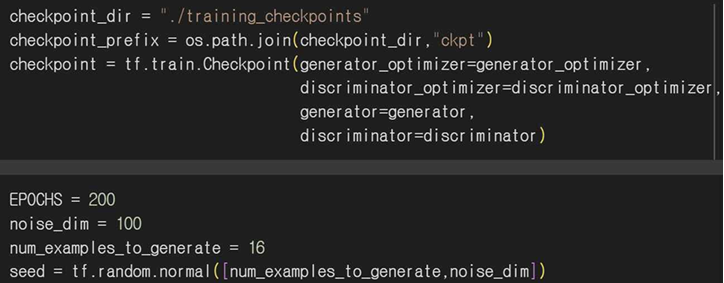
체크포인트를 설정해서 학습 중간에 모델 상태를 저장하여 나중에 복원할 수 있게 한다. GAN 학습 특성상 시간이 길게 소요되는데 긴 학습 과정에서 발생하는 중단을 방지할 수 있다.
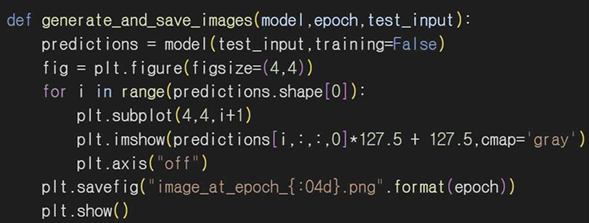
생성된 이미지를 저장하고 시각화하기 위해 generate_and_save_images 함수를 만들어준다. 주어진 에포크마다 생성된 이미지를 저장하여 학습 과정을 시각적으로 확인할 수 있다.
3-7. 모델 학습

학습 함수로 한 배치의 이미지를 사용해서 생성자와 판별자의 손실을 계산하고 그라디언트를 업데이트한다. 두 개의 GradientTape을 사용하여 각 네트워크의 손실에 대한 그라디언트를 계산한다. 여기서 그라디언트는 수학적 관점으로 볼 때 함수의 기울기를 나타내고 기계 학습에서 볼 땐 경사 하강법 역할을 한다. 손실 함수를 최소화하는 파라미터를 찾기 위해 경사 하강법을 사용해 손실 함수의 기울기를 계산하여 파라미터를 업데이트하게 되는데 이 역할을 그라디언트가 맡게 된다.
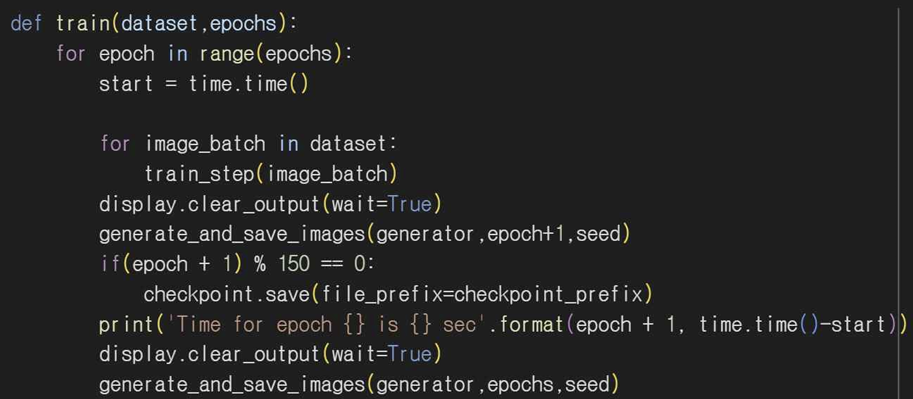
지정된 에포크 수만큼 모델을 학습시킨다. 기본 GAN 이미지 생성 코드에서 에포크 수를 200으로 설정했기 때문에 200으로 설정했고 에포크마다 train_step을 호출하여 모델을 학습하고 학습된 이미지를 저장해 결과를 확인한다. 150 스텝마다 체크포인트를 저장하여 진행 상황을 보존한다.

생성되는 이미지가 출력되도록 불러와 준다.
3-8. 생성된 이미지 분석

왼쪽부터 시간이 지남에 따라 생성된 이미지 모습이고 오른쪽 아래에 있는 이미지가 최종 출력된 이미지이다. 에포크의 수가 늘어남에 따라 반복 학습이 늘어난다는 뜻인데 이미지를 확인해보니 이미지의 형태가 점점 선명해지는 걸 확인할 수 있고 중복된 이미지의 개수가 기본 GAN보다 적은 걸 확인할 수 있었다. 그리고 3, 7, 9 등 생성된 숫자의 종류가 기본 GAN에 비해 더 다양했다.
기본 GAN 구조에서 CNN(Convolutional Neural Network)을 적용하여 이미지 생성 실습을 진행했는데 Batch Normalization 배치 정규화를 사용해서 입력 데이터가 치우쳐져 있으면 평균과 분산을 조정해주고 각 레이어에 제대로 전달되도록 학습을 진행하게 해서 중간에 끊기더라도 이어서 학습이 진행되어 확실히 기본 GAN보다 안정성 부분에서 우수하다고 느꼈다.