[2025 SWING magazine] CAPTCHA bypass (1)
1. CAPTCHA란?
Completely Automated Public Turing test to tell Computers and Humans Apart의 약자이고,‘컴퓨터와 인간을 구분하기 위한 완전히 자동화된 공개 튜링 테스트’라는 뜻이다. CAPTCHA는 다양한 인증 방식을 통해 사용자가 봇인지 인간인지를 검증하는 모든 방법, 기술을 통틀어 말하는 것이다. 자동화를 막기 위한 자동화 프로그램이다.
CAPTCHA 기술은 로그인, 계정 가입, 인터넷 결제, 설문 조사 등 다양한 분야에서 활용된다. 특히 사용자의 정보에 대한 보안이 필요한 곳에 많이 쓰인다. CAPTCHA는 테스트를 통과하면 인증 완료, 통과하지 못하면 추가적인 테스트를 요구하여 외부에서 타인의 계정을 해킹하거나 스팸을 전달하는 자동화된 소프트웨어의 접근을 차단할 수 있다. 궁극적으로 CAPTCHA는 사용자의 계정을 보호하기 위한 보안 솔루션이다.
1.1 종류, 기술
1. 텍스트 기반 방식
의도적으로 왜곡(글자 중간에 선을 긋거나, 독특한 모양으로 글자를 구기는 등)시킨 특정한 텍스트를 주고 사용자에게 그 텍스트가 무엇인지 입력하도록 요구하는 방식이다. 오늘날 가장 널리 쓰이는 방식이다.
텍스트 기반 방식에서 왜곡된 텍스트를 구현하는데 사용하는 기술은 대표적으로 다음과 같다.
CCT 기법: Connecting Characters Together의 약자로, 문자들을 서로 연결한다는 뜻이다. 이 기술은 문자들을 왜곡시킨 다음 수평적으로 연결한다. 인간의 언어가 비정형성을 가지고 있어 컴퓨터가 인간이 연결한 문자를 하나씩 분할하여 인식하기 어렵다는 점을 이용한 방식이다. 하지만 최근 연구 결과, CCT를 이용한 방식은 다른 방식에 비해 보안성이 떨어지는 것으로 밝혀졌다.
CCT를 이용한 CAPTCHA는 다음과 같이 세 가지 유형으로 분류된다.
- 문자 간 겹침이 존재하지만 노이즈 아크(직선 모양의 선이나 곡선)는 없는 유형
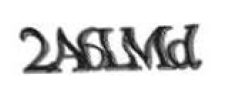
그림 1. Yahoo!에서 사용한 1)유형 - 노이즈 아크는 있지만 문자 간 겹침이 없는 유형

그림 2. Baidu에서 사용한 2)유형 - 노이즈 아크와 문자 간 겹침이 모두 없는 유형
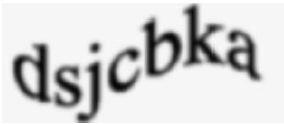
그림 3. reCAPTCHA에서 사용한 3)유형
Hollow 기법: 윤곽선 즉, 속이 비어 있는 문자들로 그려지고 그 문자들이 연결되는 방식이다. 마찬가지로 컴퓨터가 인간의 언어를 인식하기 어렵다는 점을 이용한 것이고 보안성과 사용성을 동시에 향상시키기 위해 개발되었다.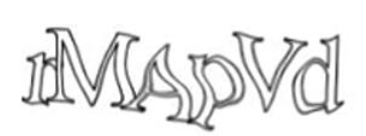
Character Isolated 기법: 문자 각각이 독립적으로 떨어져 나타난다. 연결하지 않고 독립적으로 표현하는 대신 문자에 대한 왜곡이 심한 편이다.
2. 이미지 기반 방식
텍스트 기반 방식의 자동화 공격 보안성 문제를 해결하기 위해 대안으로 쓰이는 방식이다.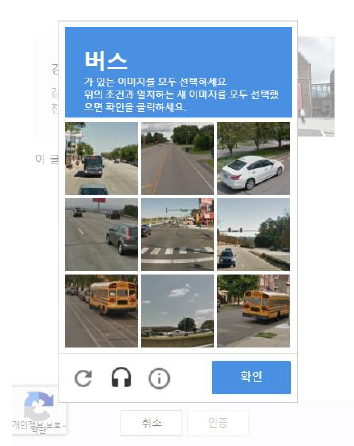
이미지 기반 방식은 사용자에게 특정한 이미지를 제공한다. 이미지들은 퍼즐 형태로 구성되어 있다. 문제에서 요청하는 이미지를 모두 알맞게 선택하면 인증이 완료되고 그렇지 않을 경우 추가적인 인증을 요구한다. 퍼즐의 형태는 보안 수준에 따라 3x3 구조부터 5x5까지 존재한다. Google과 Facebook에서 많이 사용하는 기술이다. 연구 결과에 따르면 텍스트 기반 방식 CAPTCHA에 비하면 보안성은 매우 높은 편이다. 4x4 퍼즐 기준 공격 성공률이 0.83%이다.
3. 오디오 기반 방식
재생 버튼을 누르면 음성 생성 기술을 이용하여 노이즈와 동시에 음성을 준다. 사용자가 음성을 듣고 정확한 답을 입력하면 인증이 완료되는 방식이다. 음성은 알파벳, 숫자를 읽어주거나 문장을 읽어주는 경우가 대부분이다. 그 이외에는 덧셈, 뺄셈 같은 간단한 연산을 요청하는 경우도 있다. 노이즈의 경우 사람은 잘 알아들을 수 없는 수준의 음역으로 나와 음성을 듣는 데 크게 방해가 되지는 않는다. 하지만 컴퓨터, 봇의 경우 이와 같은 노이즈도 모두 인지하기 때문에 음성을 제대로 인식하기 어렵다. 이를 이용하여 자동화 공격을 어렵게 만드는 것이다. 하지만 최근 푸리에 변환을 응용한 방법으로 노이즈를 제거한 다음 음성 인식을 하고 통과하는 경우가 늘고 있어 보안성이 높은 방법은 아니다. 많이 사용하는 CAPTCHA는 아니지만 시각 장애, 난독증, 색약 등이 있는 사람들을 위한 보조수단, 스팸 전화를 거는 기술인 SPIT(Spam over Internet Telephony)을 막는 데 활용한다.
4. 원클릭 방식(노캡챠 리캡챠)
구글의 reCAPTCHA에서 주로 볼 수 있다. reCAPTCHA v2 및 v3라고도 한다. ‘나는 로봇이 아닙니다’ 혹은 ‘I’m not a robot’이 적힌 작은 박스가 있고 빈 체크박스에 체크하면(또는 자동으로 되면) 인증이 완료되는 방식이다. v2의 경우는 사용자가 직접 체크하고(또는 자동으로 되고), v3는 체크박스가 나타나지 않고 자동으로 인증이 된다. 이 같은 방식으로 해도 인증이 가능한 이유는 사람이 CAPTCHA를 만나기 전후, 봇이 CAPTCHA를 만나기 전후 행동을 분석하여 머신 러닝으로 학습을 한 상태이기 때문이다. 만약 사용자의 행동이 봇의 경우와 비슷하다고 판단이 되면 백그라운드에서 적응형 위험 분석을 실행하고 의심스러운 트래픽을 알린다.
2. CAPTCHA 우회
2.1 우회 기술
1. 머신 러닝 방식
CAPTCHA는 ‘무작위성’이라는 특징을 가지고 있다. 머신 러닝(특히 딥러닝)은 이에 직접적으로 대응하는 방식이다. 샘플 데이터들과 정답 데이터를 주면 각 특징을 컴퓨터가 학습한다. 컴퓨터는 학습할 때 글자를 각각 분리하여 학습한다. 글자 분리를 하는 분류기의 성능이 좋을수록 정확한 학습을 하고 인식률이 높아진다. 분류기는 CNN(Convolutional Neural Neighbors), KNN(K Nearest Neighbors) 등이 있다. 이미지 기반 CAPTCHA의 경우 이보다 더 고급 기술이 필요하다. 머신 러닝 방식은 컴퓨터가 CAPTCHA를 정확하게 인식할수록 학습 단계에서 대량의 데이터셋이 필요하다. (2.2 실습으로 이어진다.)
2. 웹 스크래핑, 크롤링 방식
크롤러가 특정한 웹 페이지에 접속한 다음, 초기에 있던 HTML 콘텐츠, 이미지, 텍스트 등의 데이터를 가져온다. 해당 페이지에 CAPTCHA가 포함되어 있다면 이 부분에서 크롤링을 멈춘다. 그리고 스크래핑 도구를 이용해 해당 페이지에서 CAPTCHA 이미지를 인식한다. 그리고 크롤러는 OCR 등의 방식을 이용해 이미지의 텍스트를 분석한다. (2.2 실습으로 이어진다.)
3. OCR(Optical Character Recognition, 광학 문자 인식) 방식
OCR은 이미지의 텍스트를 기계가 읽을 수 있는 형태로 변환하는 역할이다. 웹 페이지에서 CAPTCHA 이미지를 가져오고 데이터 크기를 줄이고 OCR이 인식 후 정확한 문자로 변환할 수 있도록 먼저 이미지 전처리 과정을 수행한다. 전처리 과정은 노이즈 제거, 회색 조 변환, 이진화, 기울기 보정 등이 있다. 그다음 텍스트 검출 및 분할 단계에서는 이미지 안에 있는 텍스트를 배경으로부터 분리한다. 텍스트를 분리해 내면 문자 인식 기술로 기계가 읽을 수 있는 데이터로 변환한다. 이때 기계는 텍스트를 자신이 알고 있는 가장 비슷한 문자와 일치시킨다. 마지막으로 후처리 과정에는 문자 인식 과정에서 발생한 오류를 해결하고 유효성 검사를 통해 기계가 예상한 형식의 문자가 맞는지 확인한다.
4. 기타 방식
패킷 재전송 방식(2.2 부분에서 설명 & 실습)
유료 해결 서비스(2captcha, AZcaptcha, Dolphin 등) 사용, 1~3번 방식이 결합해 있음.
2.2 실습
1. 머신 러닝 방식(CaptchaCracker 이용)
CaptchaCracker는 CAPTCHA 이미지 문자열의 인식을 위한 머신 러닝, 딥 러닝 모델 생성, 적용 기능을 제공하는 오픈소스 파이썬 라이브러리이다.
CaptchaCracker를 이용하여 모델 학습을 시킨 다음 정부24 사이트의 CAPTCHA 이미지에 그것을 적용해 정확도를 확인할 것이다. 예측해 볼 이미지로 정부24 사이트의 CAPTCHA를 선택한 이유는 학습시킬 샘플 이미지들과 가장 유사한 형태를 가졌기 때문이다. 샘플 이미지와 타깃 이미지의 유사도가 높을수록 예측할 때 정확도가 올라간다.
Google Colab을 이용해 코드를 작성하였다.
1. 우선 !pip install CaptchaCracker로 CaptchaCracker 라이브러리를 설치한다. 설치가 되면 위 그림과 같은 결과가 나온다.
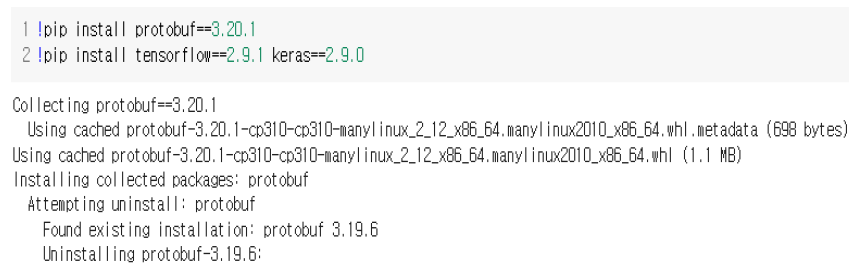
2. 3번 과정을 먼저 했을 때 protobuf 3.19.6 버전과 여러 패키지 간의 의존성 충돌(특정 패키지가 서로 다른 버전의 protobuf를 필요로 하기 때문)오류로 인해 다음 과정을 진행할 수 없을 경우 실시한다. 런타임을 초기화하고 위의 명령어를 실행한다. 조금 더 최신 버전인 protobuf의 3.20.1 버전을 설치하고 tensorflow와 밀접하게 통합된 라이브러리인 keras도 설치를 해준다. 실행하면 위와 같은 결과 아래 의존성 문제가 여전히 존재한다는 오류 문이 나올 수 있다. 하지만 protobuf로 설치된 패키지들이 기본적인 기능을 수행하는 데 문제가 없어 무시해도 된다.
Protobuf는 protocol buffers의 약자이고 데이터를 효율적으로 구조화하는데 사용된다. Tensorflow는 Google Brain 팀이 개발한 오픈소스 머신 러닝 프레임워크이다. 딥 러닝, 수치 연산 등을 위한 광범위한 라이브러리와 도구를 제공한다. Keras는 고수준 신경망 API를 가지고 있는 오픈소스 라이브러리이다. 딥러닝 작업을 빠르게 수행할 수 있도록 돕는다.

3. 수치 계산을 위한 패키지인 numpy를 1.20 이상의 버전으로 설치하고 protobuf는 3.19.6 버전, tensorflow는 2.9.1 버전을 설치한다.

4. 모델 학습시킬 샘플 CAPTCHA 이미지 파일, 모델 반복 학습으로 얻은 가중치 파일, 저장된 모델을 불러와 테스트로 예측해 볼 CAPTCHA 이미지들 모두를 Google Drive에 저장할 것이다. Colab에서 Google Drive에 접근할 수 있도록 마운트 하였다.

5. 본격적으로 모델 학습 실행에 들어간다. Glob 라이브러리를 이용해 학습시킬 이미지 파일을 찾는다. 학습시킬 이미지 파일은 sample(1) 폴더 안, train_numbers_only 폴더 안에 있는 모든 png 파일이다. 600개의 png 파일이 들어 있다. 모델 학습시킬 CAPTCHA 이미지의 너비와 높이를 각각 지정했다. CreateModel 메서드를 이용하여 학습 이미지 파일, 이미지 너비와 높이를 인자로 한 학습 모델을 생성한다. 그리고 train_model 메서드를 이용해 모델을 학습시킨다. 인자로 있는 epochs의 숫자는 반복 학습할 횟수를 의미한다. 실행하면 바로 아래와 같이 학습 상황을 확인할 수 있다.


6. 모델 학습이 끝나면 그 결과를 파일로 저장한다. 저장할 파일은 weights.h5이다. 이 파일은 저장할 때 모델 학습을 한 만큼 가중치로 저장된다. 학습을 많이 시키고 저장을 많이 할수록 데이터가 풍부해진다.

7. 저장된 모델을 불러와 CAPTCHA 이미지에 있는 글자들을 예측해 볼 것이다. 예측해 볼 이미지는 정부24 홈페이지에서 주민등록표 등본을 비회원으로 신청할 때 나오는 CAPTCHA이다. 예측할 이미지의 너비와 높이를 학습시킬 때와 똑같이 지정한다. 정부24의 CAPTCHA는 모두 6 자리 숫자로 구성되어 있으므로 글자 최대 길이는 6으로 설정하고, 라벨 각 자리가 가질 수 있는 숫자의 종류를 지정한다. 그다음 가중치 저장된 파일의 경로를 지정하고 ApplyModel 메서드를 이용해 가중치 파일, 이미지 너비와 높이, 글자 최대 길이, 라벨의 구성요소를 인자로 한 적용 모델을 만들어준다. 그리고 적용 모델을 이용하여 이미지의 라벨값 즉, 예측되는 숫자들을 출력한다. 정확하게 예측을 한 경우 결과는 위의 사진과 같이 나온다. 정부24의 서로 다른 CAPTCHA 이미지 20장을 각각 테스트해 보았다. 이에 따라 저장된 모델을 불러와 예측하는 부분은 (1)~(20)까지 존재한다.
8. 모델 학습은 총 1700번을 하였다. 학습을 많이 시키면 대체로 정확하게 예측할 확률이 높기는 하지만 학습 데이터와 머신 러닝 라이브러리 성능에 따라 한계는 있다. 1700번을 학습시킨다고 해서 무조건 아래와 같은 결과가 나오는 것은 아니다. 경우에 따라 다르게 나올 수 있다.
결과 분석
| 테스트 순서 | 원래 숫자 | 예측된 숫자 | 일치 여부 |
|---|---|---|---|
| 1 | 296337 | 296337 | O |
| 2 | 084720 | 05770[UNK] | X |
| 3 | 580274 | 530274 | X |
| 4 | 177243 | 177243 | O |
| 5 | 645038 | 645033 | X |
| 6 | 578451 | 573451 | X |
| 7 | 970836 | 970836 | O |
| 8 | 771029 | 771102 | X |
| 9 | 096340 | 096340 | O |
| 10 | 911757 | 911755 | X |
| 11 | 862274 | 952274 | X |
| 12 | 920062 | 920162 | X |
| 13 | 457872 | 457872 | O |
| 14 | 652837 | 652837 | O |
| 15 | 584735 | 534735 | X |
| 16 | 423014 | 423014 | O |
| 17 | 721797 | 721797 | O |
| 18 | 569777 | 369777 | X |
| 19 | 559958 | 559953 | X |
| 20 | 467299 | 467255 | X |
1700번의 학습량 기준으로 한 20번의 테스트에서 정부24 CAPTCHA 숫자 전체를 정확하게 예측한 경우는 총 8번이다. 40%의 정확도이다. 생각보다 정확하게 예측할 확률이 낮다는 생각이 들 수 있다. 하지만 한 글자씩 비교하면서 정확도를 조금 더 세세하게 따지면 그리 낮지 않다. CAPTCHA 이미지 하나에 숫자가 6개씩 있고 그것이 20가지 존재하므로 총 120가지의 숫자들이 있다. 이 중 결과에 UNK(Unknown, 예측 실패)가 나온 경우는 몇 개의 숫자가 일치하는지 정확하게는 알 수 없다. 그것을 반영하면 불일치하는 숫자는 120개 중 최소 16개에서 최대 20개인 것을 알 수 있다. 그러면 정확하게 예측한 숫자는 100~104개이다. 숫자 하나씩 살펴보면 정확도는 83.33% ~ 86.66%이고 꽤 높은 것을 알 수 있다. 만약 CaptchaCracker보다 모델 학습과 예측하는 기능이 더 뛰어난 도구를 사용한다면 100%에 육박하는 결과를 얻을 수 있을 것으로 보인다.
CAPTCHA의 종류 중 적어도 텍스트 방식의 경우 머신 러닝을 통한 우회로부터 상당히 취약하다는 것을 알 수 있었다.
20가지 CAPTCHA 이미지를 모두 실습한 것은 아래 사이트에 업로드 해 두었다.
https://github.com/hyemsnail/captcha_project/blob/main/captchacracker.ipynb
이상으로 여기까지 하고 이번 글을 마치겠다. 분량 이슈로 나머지 실습 2가지와 우회 방지 방법은 다음 편에 작성하겠다.